Structr
Admin User Interface
Overview
The Structr Admin User Interface is a web-based console for building and managing Structr applications. From here, you can design your data model, build pages, manage users, and monitor your running application.
Quick Reference
| I want to… | Go to |
|---|---|
| Define data types and relationships | Schema |
| Write business logic and methods | Code |
| View and edit data in the database | Data |
| Build web pages and templates | Pages |
| Manage static files (CSS, JS, images) | Files |
| Manage users, groups, and permissions | Security |
| Export or import my application | Dashboard |
| Run scripts and queries interactively | Admin Console (Ctrl+Alt+C) |
Interface Structure
The interface is organized around a header bar that stays visible across all areas. The main navigation on the left side of the header takes you to the different functional areas: Dashboard, Pages, Files, Security, Schema, Code, Data, and more. Less frequently used items are available in the burger menu, which also contains the logout link. You can configure which items appear in the main navigation through the UI Settings on the Dashboard.
On the right side of the header, tools are available regardless of which area you are working in:
Search
The magnifying glass icon opens a global search across all your data.
Configuration
The wrench icon opens the Configuration Interface in a new browser tab. This separate interface provides access to all runtime settings that control Structr’s behavior, from database connections to scheduled tasks. It requires authentication with the superuser password defined in structr.conf, adding an extra layer of security for these sensitive operations. For details, see the Configuration Interface section below.
Admin Console
The terminal icon opens the Admin Console – a Quake-style terminal that slides down from the top of the screen. This is a powerful REPL for executing JavaScript, StructrScript, Cypher queries, and administrative commands. You can also open it with Ctrl+Alt+C.
Notifications
The bell icon shows notifications and system alerts.
The Main Areas
Dashboard
This is the default landing page after login. Here you can view system information, check server logs, and use deployment tools to export and import your application.
Pages
This is the visual editor for building web pages. You can use the tree view to see your page structure, drag and drop widgets, and preview your pages in real time.
Files
This is where you manage your static assets – CSS, JavaScript, images, and documents. You can upload files, organize them in folders, and reference them in your pages.
Security
Here you can manage users and groups, configure resource access grants, and set up CORS.
Schema
This is the visual data modeler. Types appear as boxes, relationships as connecting lines. You can drag them to arrange the layout and click to edit their properties.
Code
Here you can write and organize your business logic. The same types as in the Schema area are displayed, but organized for writing and editing methods rather than visualizing relationships.
Data
Here you can browse and edit the objects in your database. Select a type, view all instances in a table, and edit values directly.
Flows
This is a visual workflow designer where you can create automated processes and data transformations.
Job Queue
This area shows scheduled jobs and background tasks. Jobs created with $.schedule() appear here and can be monitored or cancelled. (Note: This area is currently labeled “Importer” in the UI but will be renamed in a future release.)
Localization
Here you can manage translations for multi-language applications.
Graph
This is an interactive graph explorer where you can visualize your data objects and their relationships.
Virtual Types
Here you can configure dynamic types that transform or aggregate data from other sources.
Mail Templates
Here you can create and edit email templates used in automated notifications.
Browser Compatibility
The Admin UI is supported in Chrome, Firefox, Safari, and Edge. For the best experience, keep your browser updated to the latest version.
Dashboard
The Dashboard provides system information, server logs, deployment tools, and configuration options for the Admin UI. This is the default landing page after login and gives you a quick overview of the system state.
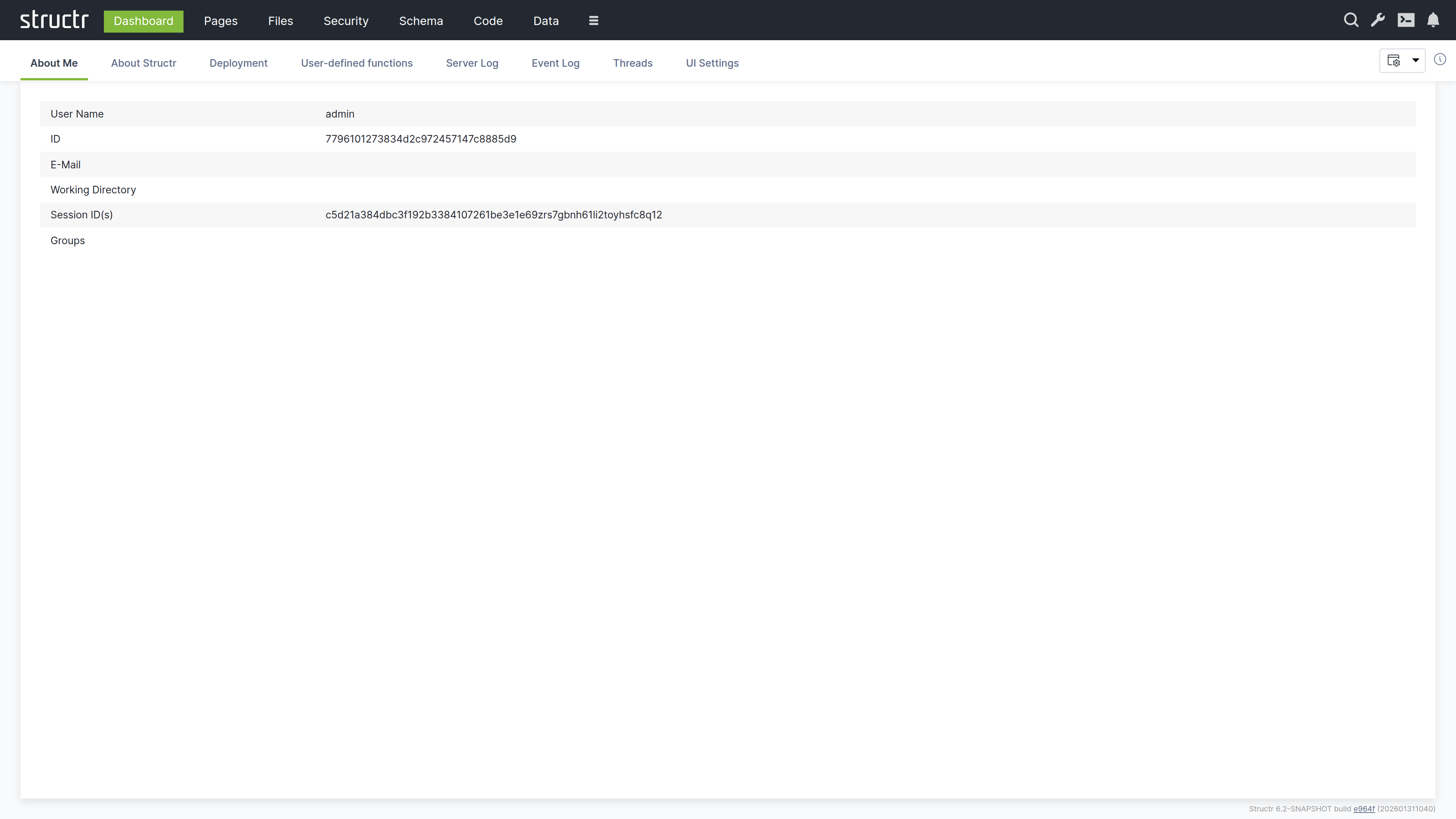
About Me
This tab shows information about the currently logged-in user. You can verify your identity, check which groups you belong to, and see your active sessions. This is useful when troubleshooting permission issues or when working with multiple accounts.
The tab displays:
- Username and UUID
- Email address
- Working directory
- Session IDs
- Group memberships
The Session ID is particularly useful for debugging. If you need to see your application from another user’s perspective, you can copy their Session ID from the table and set it in your browser. This allows you to experience exactly what that user sees without knowing their password.
About Structr
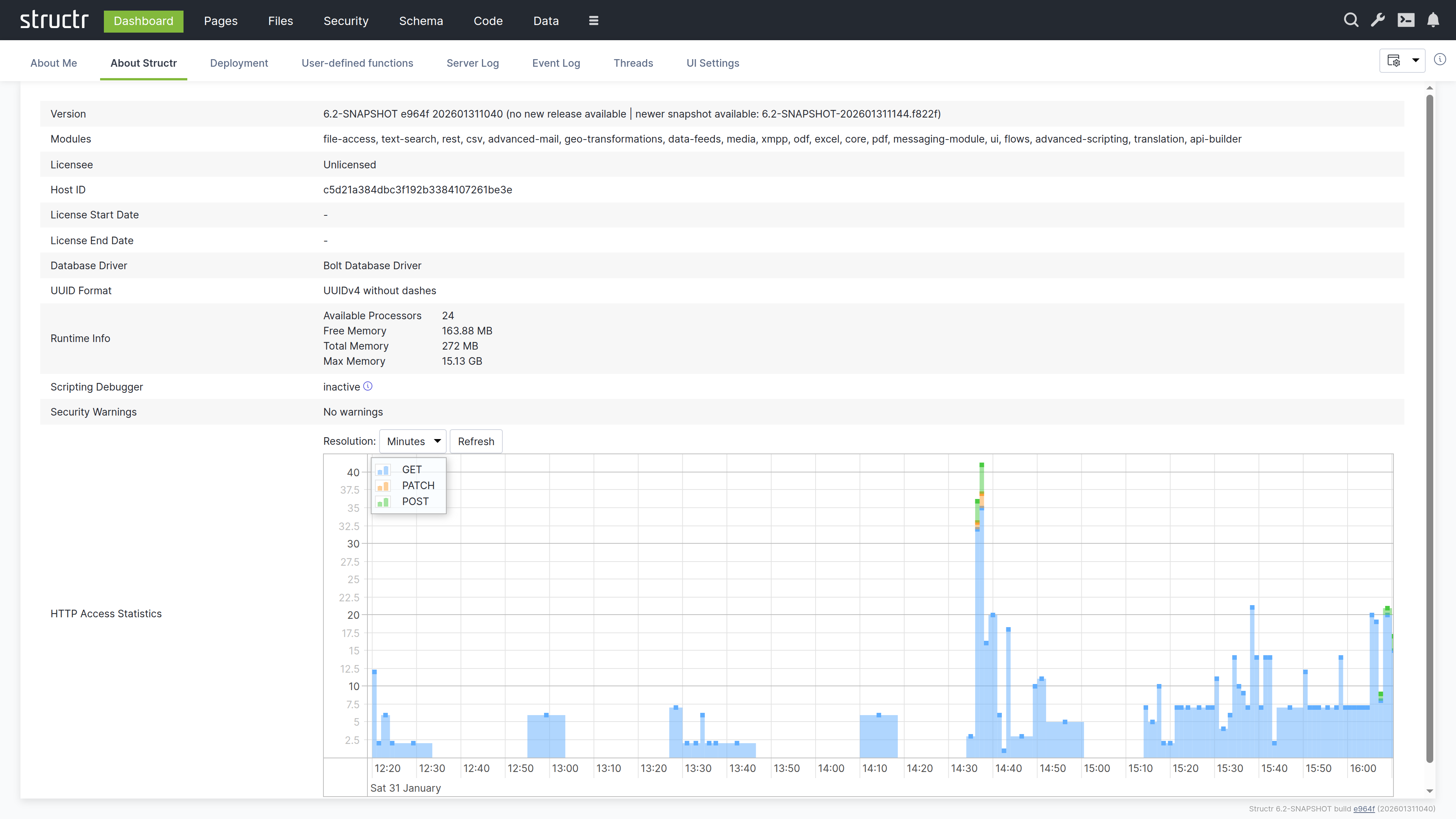
This tab shows detailed information about the Structr server instance. You can verify which version is running, which modules are available, and whether your license is valid.
Version and Modules
The version number identifies the exact build you are running. Indicators show whether newer releases or snapshots are available. Below the version, you will see a list of all active modules. Modules extend Structr’s functionality – for example, the PDF module adds PDF generation capabilities, and the Excel module enables spreadsheet import and export.
License and Database
The license section shows your licensee name, host ID, and the validity period (start and end date). You need the host ID when requesting a license from Structr.
The database section shows which driver is in use. Structr supports both embedded and external Neo4j databases.
UUID Format
This displays the current UUID format. Structr supports UUIDs with and without dashes. The format is configured at installation time and should not be changed afterwards.
Runtime Information
This section shows server resource information: number of processors, free memory, total memory, and maximum memory. You can monitor these values to assess server capacity and diagnose performance issues.
Scripting Debugger
This shows whether the GraalVM scripting debugger is active. The debugger allows you to set breakpoints and step through JavaScript code using Chrome DevTools. To enable it, set application.scripting.debugger = true in structr.conf. See Debugging JavaScript Code for details.
Access Statistics
This is a filterable table showing request statistics: timestamps, request counts, and HTTP methods used. You can use this to analyze usage patterns and identify unusual access behavior.
Deployment
This tab provides tools for exporting and importing Structr applications and data.
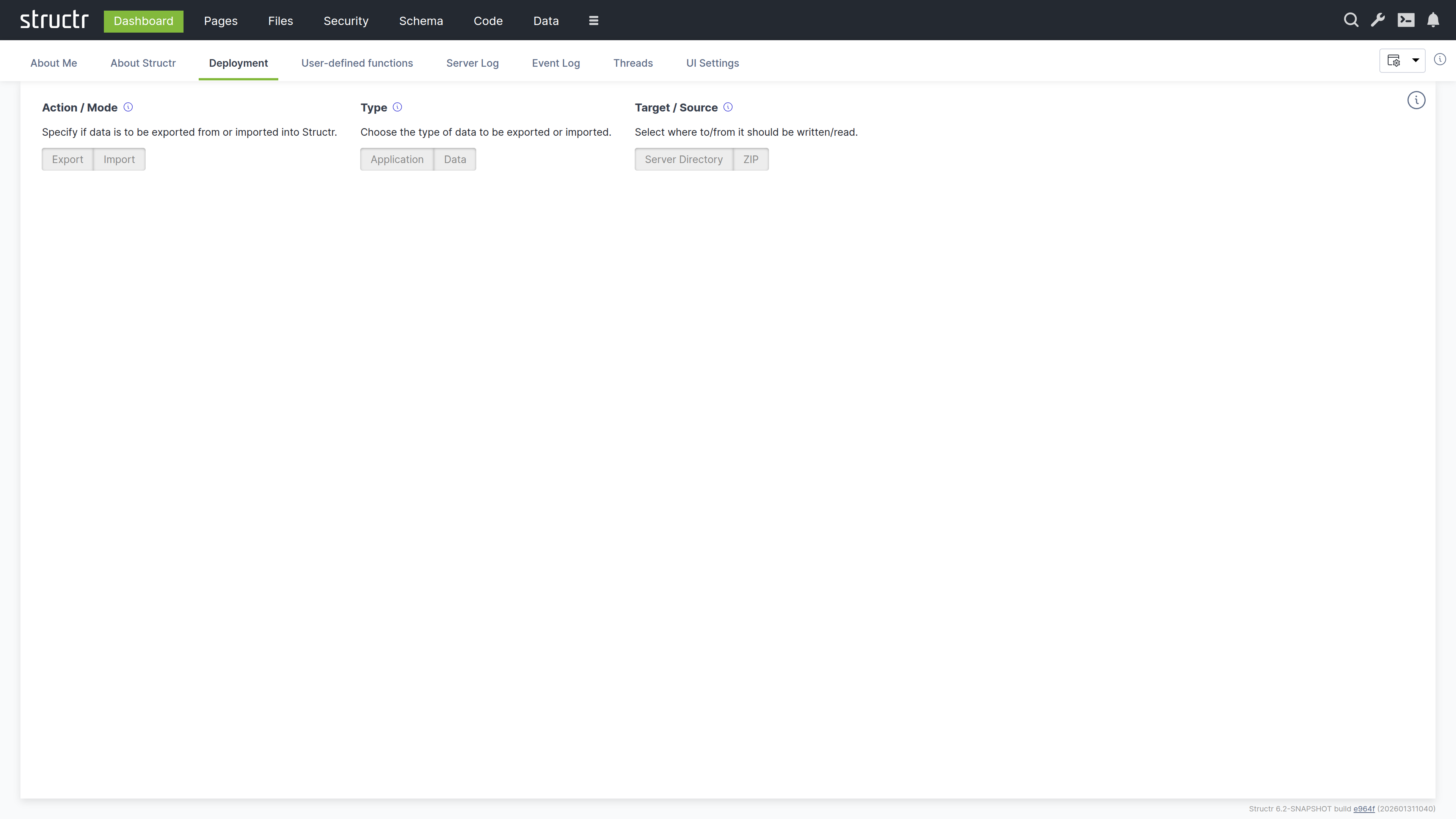
Application Deployment
The upper section handles application deployment – exporting and importing the structure of your application (schema, pages, files, templates, security settings, configuration).
Four options are available:
- Export application to local directory – Enter an absolute path on the server filesystem and click the button to export
- Export and download application as ZIP file – Downloads the export directly to your browser
- Import application from local directory – Enter the path to an existing export and click to import
- Import application from URL – Enter a URL to a ZIP file and click to download and import
Data Deployment
The lower section handles data deployment – exporting and importing the actual objects in your database.
- Export data to local directory – Select which types to export, enter a path, and click to export
- Import data from local directory – Enter the path to an existing data export and click to import
You can follow the progress of any export or import operation in the Server Log tab or via the notifications in the UI.
For details on the export format, pre/post-deploy scripts, and alternative deployment methods, see the Deployment chapter in Operations.
User-Defined Functions
This tab displays a table of all user-defined functions in the system. You can view and execute any function directly from this interface.
Each function is listed with its name and can be executed by clicking on it. This provides a quick way to run maintenance tasks, test functions, or trigger administrative operations without using the API or Admin Console.
Server Log
This tab displays the server log in real-time. The log contains technical information about what Structr is doing: startup messages, errors, warnings, request processing, and transaction details.
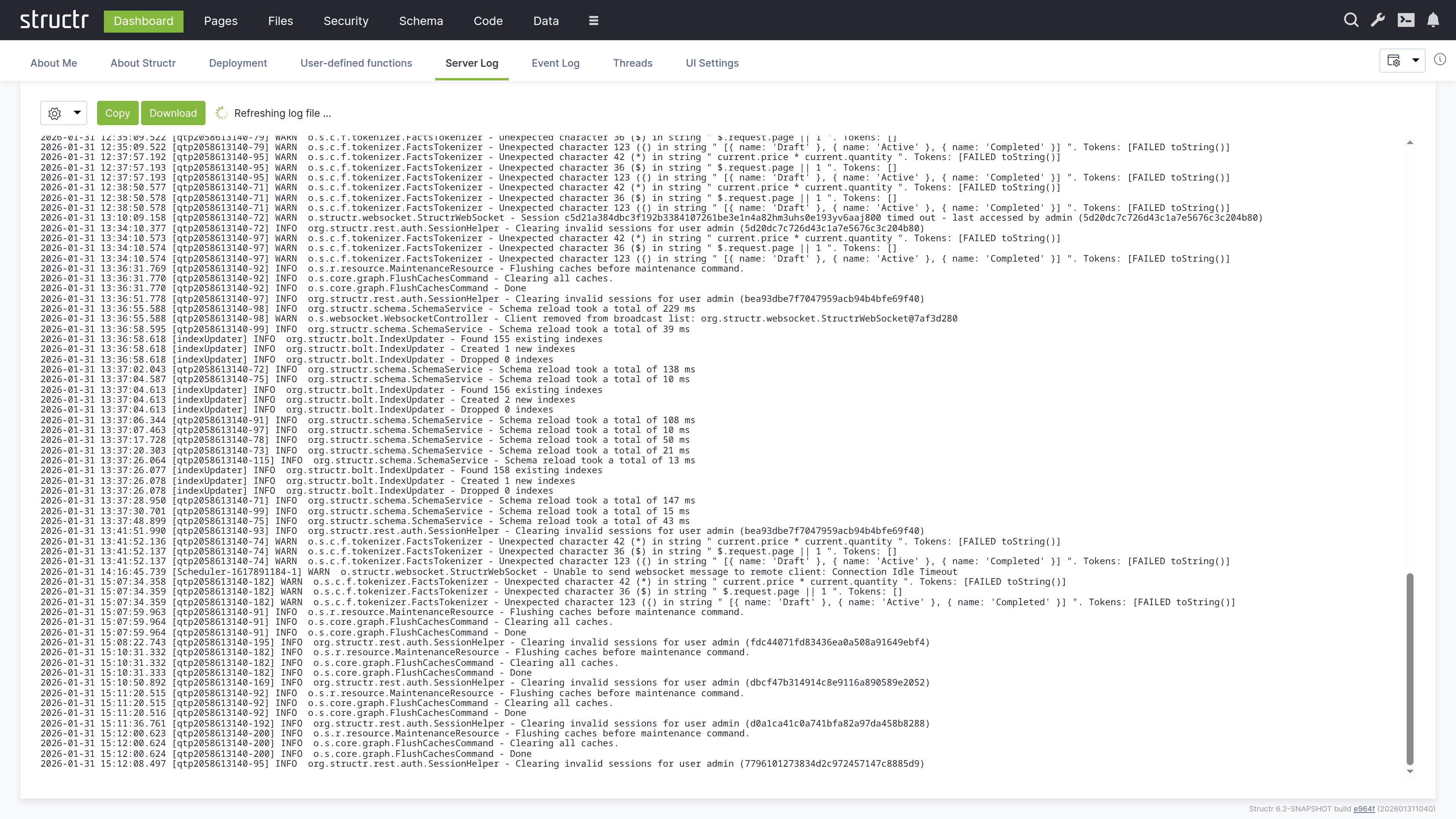
Controls
The log refreshes every second by default. You can click inside the log area to pause auto-refresh when you need to read a specific message. The available controls are:
- Copy to clipboard
- Download log file
- Refresh interval (1–10 seconds, or manual)
- Number of lines to display
- Log source selection (Structr supports multiple log files when rotation is enabled)
Log Format
Each log entry follows the format: Date Time [Thread] Level Logger - Message
For example:
2026-01-28 09:40:18.126 [main] INFO org.structr.Server - Starting Structr 6.1-SNAPSHOT
The log levels are INFO (normal operation), WARN (potential issues that do not prevent operation), and ERROR (problems that need attention).
Event Log
This tab shows a structured view of system events: API requests, authentication events, transactions, and administrative actions. Unlike the server log which contains free-form text, the event log presents events as filterable table rows with consistent columns.
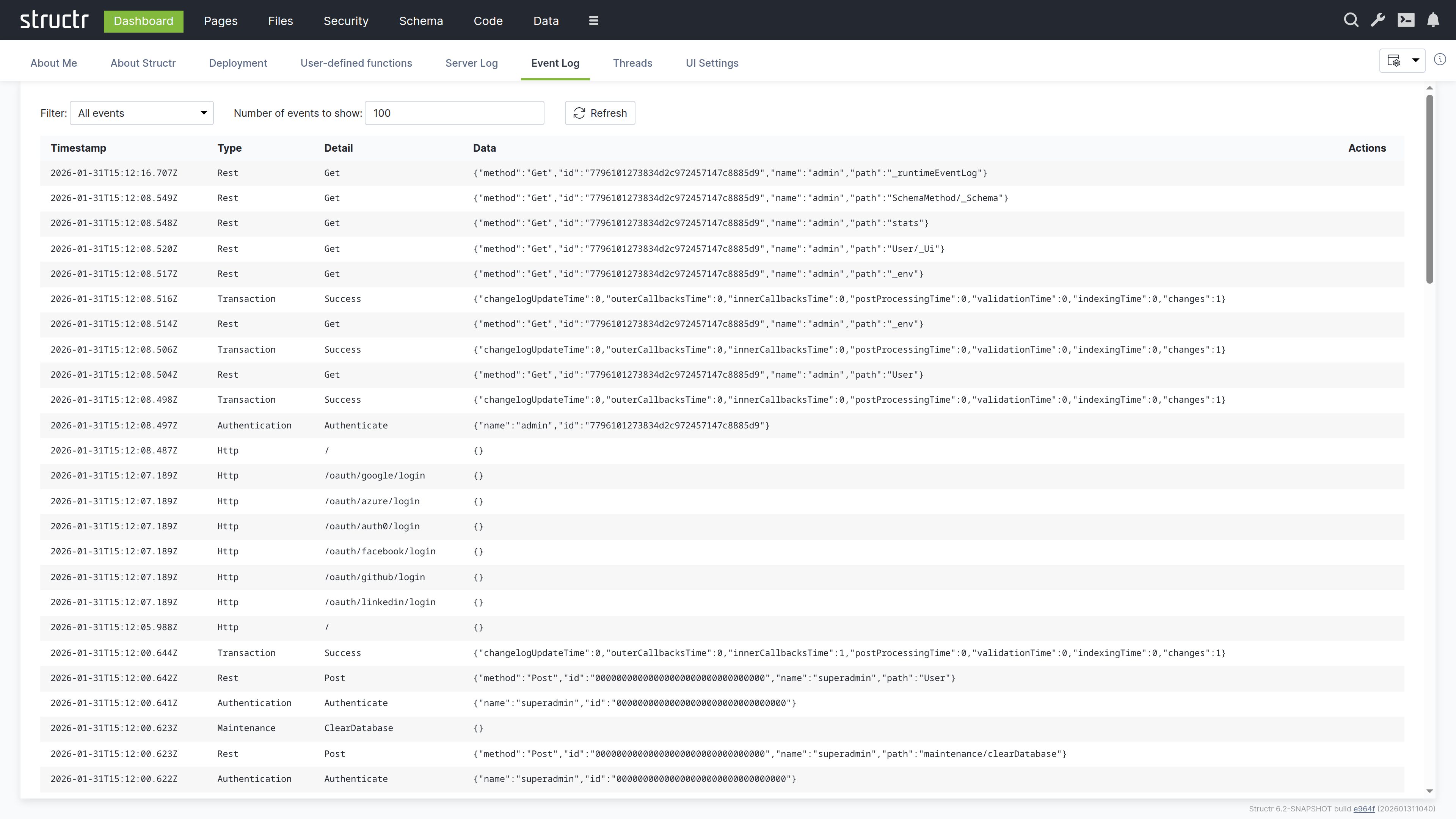
Event Types
The following event types are tracked:
- Authentication – Login and logout events with user information
- Rest – API requests with method, path, and user details
- Http – Page requests and OAuth login attempts
- Transaction – Database transactions with performance metrics (changelog updates, callbacks, validation, indexing times)
- Maintenance – Administrative commands
Using the Event Log
The event log does not auto-refresh. Click the refresh button to update it. You can filter by event type to focus on specific activities. The transaction events include timing breakdowns that can help you identify performance bottlenecks.
Threads
This tab lists all threads running in the Java Virtual Machine. Each row shows the thread name, state, and stack trace. You can use this tab to diagnose hanging requests, infinite loops, or deadlocks.
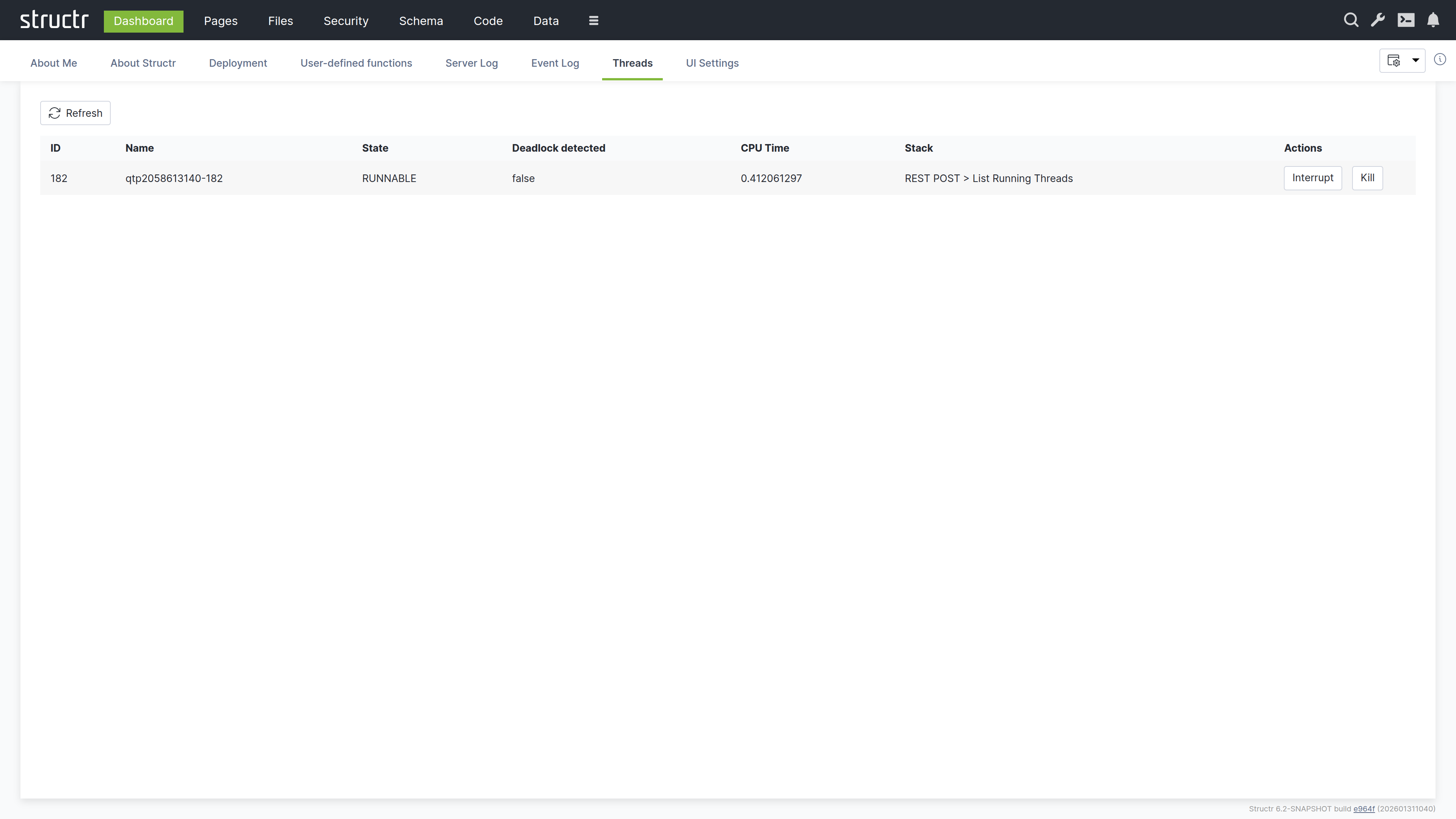
Thread Management
Two actions are available for each thread:
- Interrupt – Requests graceful termination
- Kill – Forces immediate termination (use with caution)
Long-running threads may indicate problems in your application code, such as infinite loops or deadlocks.
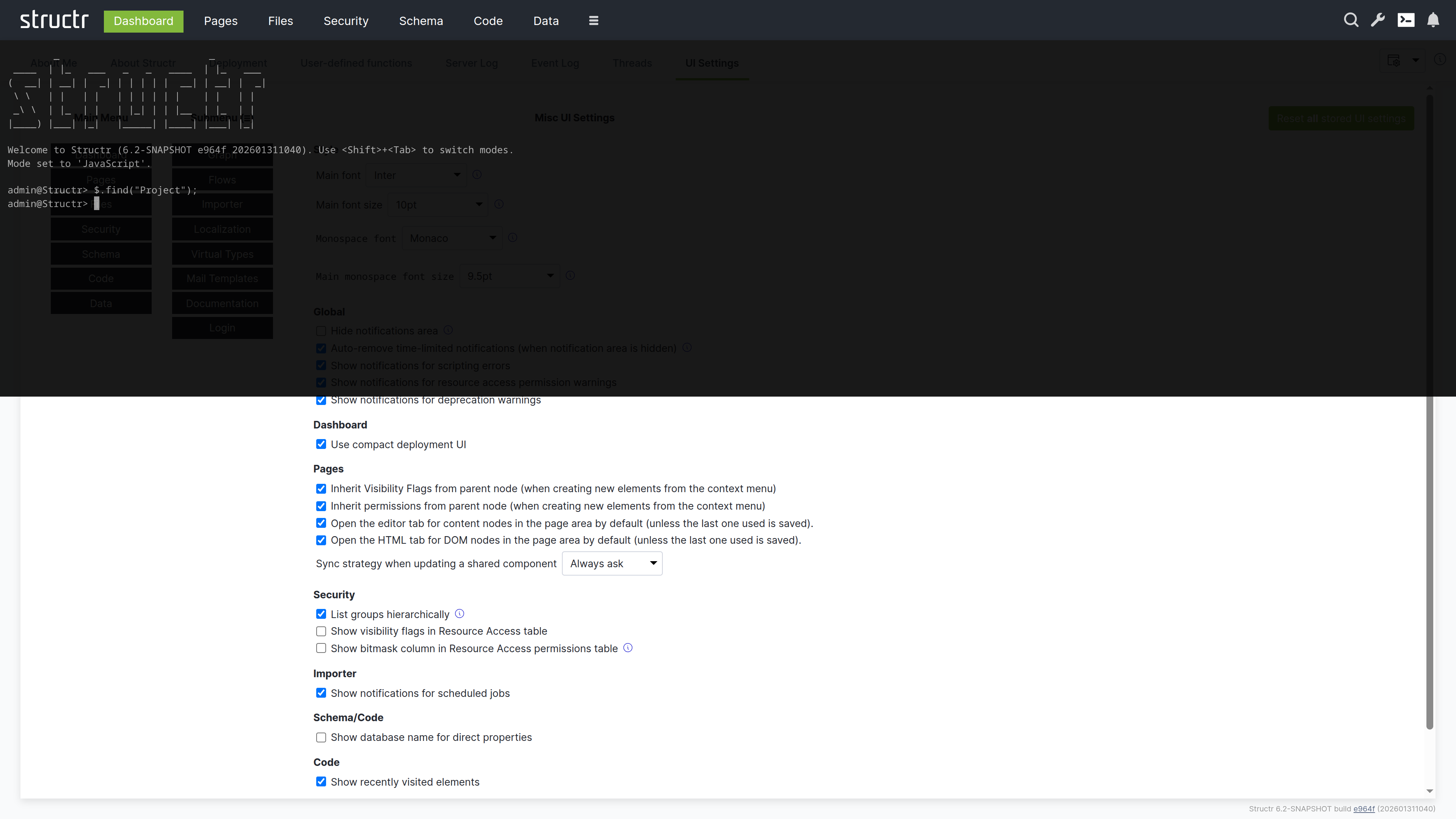
UI Settings
This tab lets you configure the Admin UI appearance and behavior. Changes take effect immediately and are stored per user.
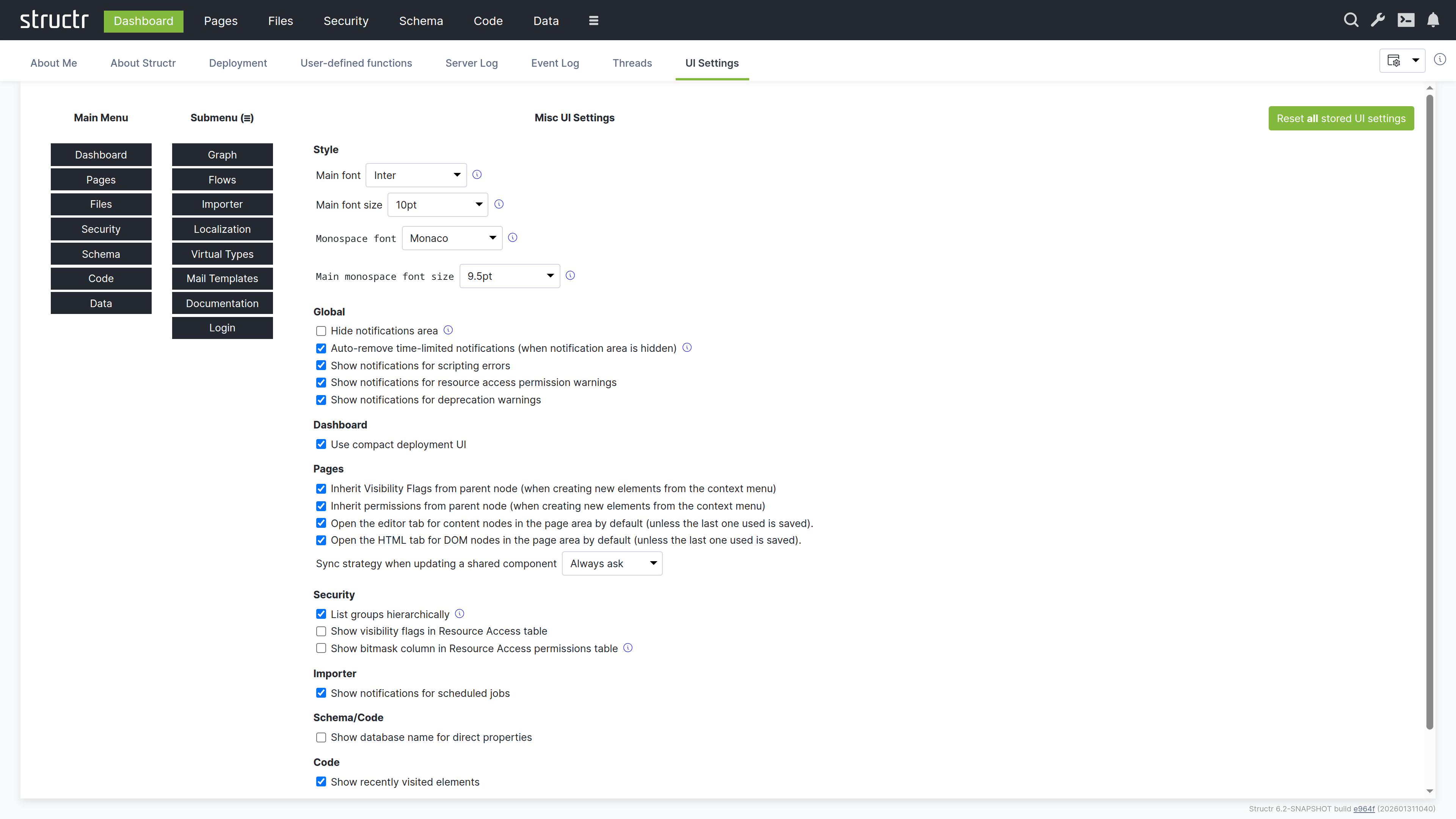
Menu Configuration
Here you can configure which items appear in the main navigation bar and which are moved to the burger menu. This lets you prioritize the areas you use most frequently.
Font Settings
You can set the main font, font size, and monospace font for the Admin UI. The monospace font is used in code editors and log displays.
Behavior Settings
This section contains checkboxes for various UI behaviors, grouped by area:
- Global – Notification display and behavior
- Dashboard – Compact deployment UI option
- Pages – Inheritance behavior when creating elements, default tab selection
- Security – Group display, visibility flags in tables
- Importer – Job notifications
- Schema/Code – Database name display
- Code – Recently visited elements
- Data – Array size display limits
Note that the settings relevant to a specific area also appear in a Settings menu within that area. For example, the Pages settings are available both here and in the Pages area’s own Settings menu. This allows you to adjust settings without navigating back to the Dashboard.
Admin Console
The Admin Console is a text-based interface for advanced administration tasks. It provides a REPL (read-evaluate-print loop) where you can execute JavaScript, StructrScript, Cypher queries, Admin Shell commands, and REST calls directly.
Opening the Console
The Admin Console is integrated into the Admin UI as a Quake-style terminal that slides down from the top of the screen and overlays the current view. You can open it in two ways: click the terminal icon in the header (available in all areas), or press Ctrl+Alt+C (on macOS: Control+Option+C) to toggle the console.
Console Modes
The console has five modes that you can cycle through by pressing Shift+Tab.
JavaScript Mode
A full JavaScript REPL where you can execute JavaScript expressions. Variables you declare persist across commands, so you can build up state interactively. This mode is useful for data manipulation, quick fixes, and exploration.
// Find all projects and store in a variable
let projects = $.find('Project');
// Use the variable in subsequent commands
$.print(projects.length + ' projects found');
// Modify data interactively
for (let p of projects) {
if (p.status === 'draft') {
$.set(p, 'status', 'archived');
}
}
Since all parts of a Structr application are stored in the database, you can use JavaScript mode to create schema types and data objects directly:
$.create('SchemaNode', { name: 'Project' });
$.create('Project', { name: 'Project #1' });
$.find('Project').map(p => p.name).join(', ');
StructrScript Mode
Execute StructrScript expressions directly. This mode is useful for testing expressions before using them in pages or templates. Unlike JavaScript mode, you cannot declare persistent variables here.
find('User', 'name', 'admin')
join(extract(find('Project'), 'name'), ', ')
Cypher Mode
Execute Cypher queries directly against the Neo4j database. This mode is useful for database maintenance tasks like setting labels, modifying data, or exploring relationships.
MATCH (n:Project)-[:HAS_TASK]->(t:Task) RETURN n.name, count(t)
By default, the output is limited to 10 results to prevent overwhelming the display with large result sets. If your query returns more objects, Structr displays an error message asking you to use LIMIT in your query. You can change this limit through the application.console.cypher.maxresults setting in the Configuration Interface.
Admin Shell Mode
A command-line interface for administrative tasks. Type help to see available commands, or help <command> for detailed information about a specific command.
export
Exports the Structr application to a directory on the server filesystem.
export <target>
- target - Absolute path to the target directory
export-data
Exports data from specific types to a directory.
export-data <target> <types>
- target - Absolute path to the target directory
- types - Comma-separated list of type names to export
import
Imports a Structr application from a directory on the server filesystem.
import <source>
- source - Absolute path to the source directory
import-data
Imports data for specific types from a directory.
import-data <source> [doInnerCallbacks] [doCascadingDelete]
- source - Absolute path to the source directory
- doInnerCallbacks - Run onCreate/onSave methods during import (default: false)
- doCascadingDelete - Enable cascading delete during import (default: false)
file-import
Imports files directly from a server directory into Structr’s virtual filesystem.
file-import <source> <target> [mode] [existing] [index]
- source - Path to a directory on the server
- target - Target path in Structr’s virtual filesystem
- mode - copy (default) or move
- existing - skip (default), overwrite, or rename
- index - Fulltext-index imported files: true (default) or false
init
Rebuilds indexes, sets UUIDs, or updates labels on nodes and relationships.
init [node|rel] <operation> [for <type>]
- operation - index, ids, or labels
- node|rel - Restrict operation to nodes or relationships
- for
- Restrict operation to a specific type
user
Manages user accounts in the database.
user <command> [arguments]
- list - List all users
- add
[ - Create a new user] [isAdmin] - delete
- Delete a user - password
REST Mode
Execute REST API calls directly from the console. This mode simulates external access to the Structr REST API. Requests run without authentication by default, allowing you to test Resource Access Grants and verify how your API behaves for unauthenticated users. Type help to see available commands.
get
Executes a GET request and returns the result as JSON.
get <URI> [return <jsonPath>]
- URI - REST endpoint, starting with a slash
- jsonPath - Extract specific values using a JSON path
post
Executes a POST request to create new objects or call schema methods.
post <URI> <JSON>
- URI - REST endpoint
- JSON - Request body
put
Executes a PUT request to modify existing objects.
put <URI> <JSON>
- URI - REST endpoint including the object ID
- JSON - Properties to update
del
Executes a DELETE request to remove objects.
del <URI>
- URI - REST endpoint including the object ID
auth
Sets authentication credentials for all subsequent requests in the current session. Run without parameters to reset credentials and return to unauthenticated mode.
auth [<username> <password>]
- username - Username for authentication
- password - Password for authentication
as
Executes a single command with the credentials of a specific user without changing the session authentication.
as <user:password> <command>
- user:password - Credentials in the format username:password
- command - The REST command to execute
Example Session
anonymous@Structr> auth admin admin
admin@Structr> get /Project
GET http://0.0.0.0:8082/structr/rest/Project
HTTP/1.1 200 OK
{ "result": [...], "result_count": 3 }
admin@Structr> post /Project { name: "New Project" }
HTTP/1.1 201 Created
SSH Access
The Admin Console functionality is also available via SSH for admin users. Connect to the configured SSH port (default 8022):
ssh -p 8022 admin@localhost
You can configure the SSH port through the application.ssh.port setting in the Configuration Interface. Authentication works via password or public key. For public key authentication, store the user’s public key in the publicKey property on the user node.
Related Topics
- Business Logic - JavaScript and StructrScript syntax and capabilities
- Deployment - Using Admin Shell commands for application export/import
- Configuration Interface - Changing console-related settings
Schema
The Schema area is the visual editor for designing your data model. Types appear as boxes on a canvas, and relationships appear as connecting lines between them. You can drag types to arrange them, click to edit their properties, and draw connections between types to create relationships.
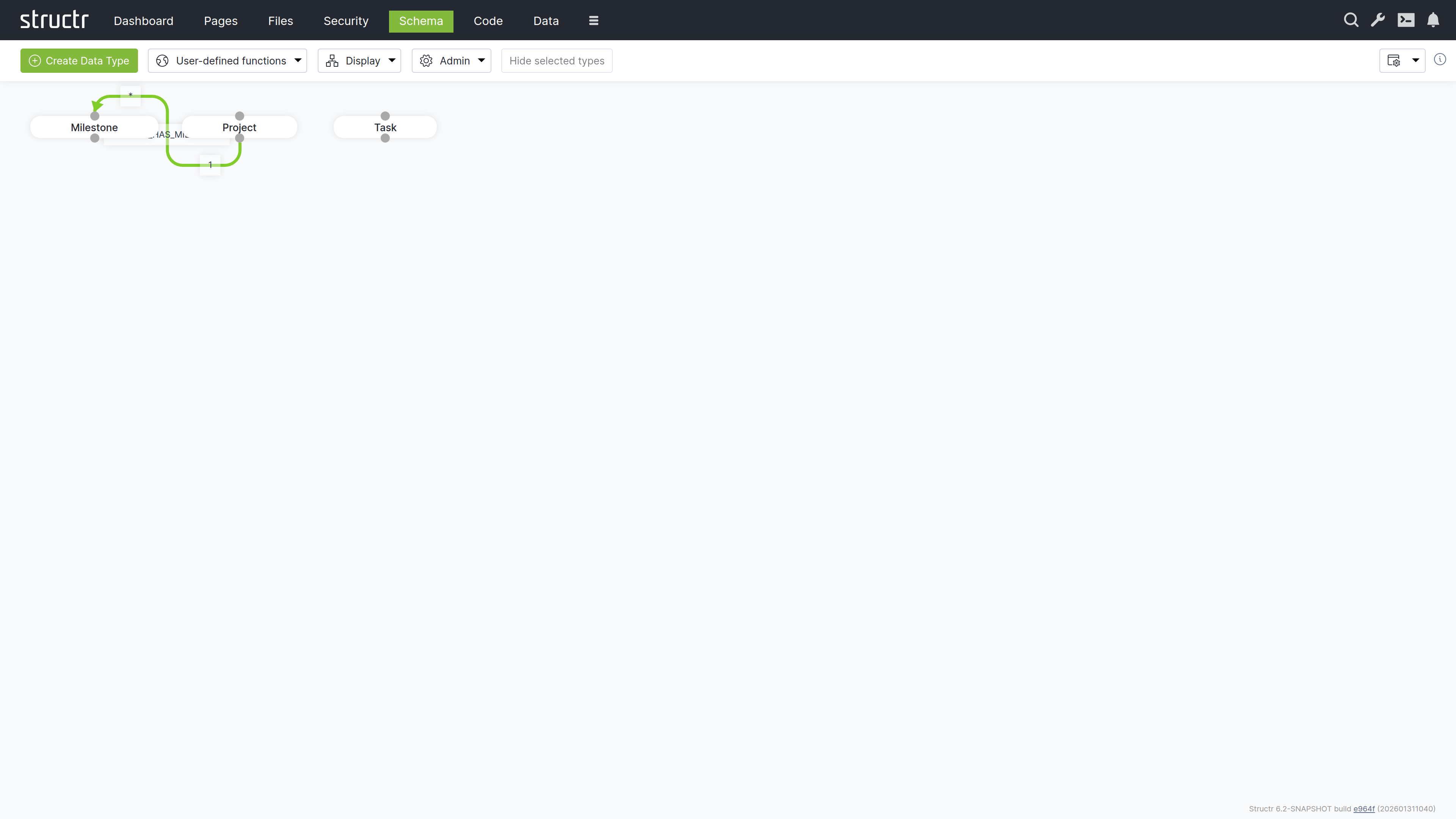
The Canvas
The main area displays your data model as a graph. Each type appears as a box showing the type name. Hover over a type to reveal the pencil icon (edit) and delete icon. Connection points at the top and bottom of each box let you create relationships by dragging from one type to another – drag from the source type’s connector to the target type’s connector, and Structr opens the relationship configuration dialog.
Navigating Large Schemas
Use the mouse wheel to zoom in and out. Click and drag on empty canvas space to pan. For applications with many types, these controls help you focus on the part of the schema relevant to your current task.
Relationship Colors
Relationship lines are color-coded:
- Green – Normal relationships
- Orange – Relationships configured for permission propagation (see User Management for details on graph-based permission resolution)
Schema and Data Are Loosely Coupled
The schema and your data are loosely coupled. If you delete a type from the schema, the type definition and its relationships are removed, but the data objects of that type remain in the database. You can recreate the type later and the data becomes accessible again. This flexibility is useful during development but means you need to manage data cleanup separately from schema changes.
Editing Types and Relationships
Click the pencil icon on a type box to open the Edit Type dialog. Click on a relationship line to open the Edit Relationship dialog. Both dialogs provide access to all configuration options – properties, methods, views, and more. For details on these options, see the Data Model chapter.
Secondary Menu
The menu bar above the canvas provides tools for managing your schema.
Create Type
The green button opens the Create Type dialog where you enter a name and select traits for the new type. After creation, the Edit Type dialog opens automatically so you can add properties and configure the type further.
Snapshots
The Snapshots menu lets you save and restore schema states. A snapshot captures your entire schema definition at a point in time.
- Create Snapshot – Saves the current schema state with a name you provide
- Restore Snapshot – Replaces the current schema with a previously saved snapshot
- Delete Snapshot – Removes a saved snapshot
Snapshots are useful before making significant schema changes, allowing you to roll back if needed.
User Defined Functions
Opens a table listing all global schema methods. This is a legacy location – the same methods are more conveniently accessible in the Code area under Global Methods.
Display Menu
Controls the visual appearance of the schema editor.
Type Visibility
Opens a dialog where you show or hide types on the canvas. Types are grouped into categories: Custom Types, User/Group Types, File Types, HTML Types, Flow Types, Schema Types, and Other Types. Each type has a checkbox to toggle its visibility.
This is essential for focusing on specific parts of the schema. In a typical application, you work primarily with your custom types and rarely need to see the built-in HTML or Flow types.
Display Options
Two toggles control what information appears on the canvas:
- Relationship Labels – Shows or hides the relationship names on connecting lines
- Inheritance Arrows – Shows or hides arrows indicating trait inheritance
Edge Style
Controls how relationship lines are drawn: Flowchart, Bezier, State Machine, or Straight. Choose whatever makes your schema most readable – Flowchart works well for hierarchical schemas, while Straight lines are cleaner for simpler models.
Layouts
Schema layouts save the visual arrangement of types on the canvas. If you’ve organized a complex schema to make it readable, you can save that layout and restore it later. You can also export layouts to share with team members or import layouts they’ve created.
- Save Current Layout – Saves the current arrangement
- Restore Layout – Loads a previously saved layout
- Export Layout – Downloads the layout as a file
- Import Layout – Loads a layout from a file
- Delete Layout – Removes a saved layout
Reset Layout / Reset Zoom
Reset Layout returns all types to their default positions. Reset Zoom returns to the default zoom level.
Apply Automatic Layout
An experimental feature that arranges types on the canvas automatically. Results vary depending on schema complexity.
Admin Menu
The Admin menu provides database maintenance functions.
Indexing – Nodes
- Rebuild Index – Recreates indexes for all or selected node types. Run this after adding indexed properties to a type that already has data.
- Add UUIDs – Adds UUIDs to nodes that lack one. Use this when importing data from an external Neo4j database.
- Create Labels – Creates Neo4j labels based on the type property. Use this when importing data that has type values but is missing the corresponding labels.
Indexing – Relationships
- Rebuild Index – Recreates indexes for relationships.
- Add UUIDs – Adds UUIDs to relationships imported from an external database.
Rebuild All Indexes
Triggers a complete rebuild of all indexes for both nodes and relationships. Use this after importing data or when you suspect index inconsistencies.
Maintenance
- Flush Caches – Clears internal caches. Rarely needed in current versions.
- Clear Schema – Removes all custom types and relationships from the schema. Use with extreme caution – this erases your entire data model definition (though not the data itself).
Settings
The gear icon opens configuration options for the Schema area. These are the same settings available in the Dashboard under UI Settings, filtered to show only schema-relevant options.
Data
The Data area is a generic interface for viewing and editing all objects in your database. You can select a type from the list, view all its instances in a table, and edit values directly. This is useful for data inspection, quick fixes, bulk operations, and CSV import/export.
Browsing Your Data
The left sidebar displays all your custom types. Click on a type to view its instances in a paginated table on the right.
Type Filter
A filter button above the list lets you expand what’s shown. You can include:
- Custom Types (shown by default)
- Custom Relationship Types
- Built-In Relationship Types
- HTML Types
- Flow Types
- Other Types
Recently Used Types
Below the type list, recently accessed types are shown for quick navigation.
The Data Table
When you select a type, the main area displays all objects of that type in a table. Each row represents an object, and each column represents a property.
Pagination and Views
Above the table, the following controls are available:
- Pager controls for navigating through pages
- A page size input to set how many objects appear per page
- A view dropdown to select which properties appear as columns
Editing Values
System properties (like id and type) are read-only, but you can edit other properties directly in the table cells by clicking on them.
Navigating Related Objects
Properties that reference other objects are clickable. Click on one to open a dialog showing the related object, where you can view and edit it. From that dialog, you can navigate further to other related objects, allowing you to traverse your entire data graph without leaving the Data area.
Creating Relationships
For relationship properties, a plus button appears in the table cell. Click it to open a search dialog limited to the target type. Select an object to create the relationship. The dialog respects the cardinality defined in the schema – for one-to-one or many-to-one relationships, selecting a new object replaces the existing one.
Creating and Deleting Objects
Create Button
The Create button in the header creates a new object of the currently selected type. The button label changes to reflect the type currently being viewed.
Delete All
The “Delete All Objects of This Type” button does exactly what it says – use it with caution. A checkbox lets you restrict deletion to exactly this type; if unchecked, objects of derived types are also deleted.
Import and Export
Export as CSV
Downloads the current table view as a CSV file.
Import CSV
Opens the Simple CSV Import dialog. See the Importing Data chapter for details on the import process and field mapping.
Search
The search box in the header searches across your entire database, not just the currently selected type. Results are grouped by type, making it easy to find objects regardless of their location. Click the small “x” at the end of the search field to clear the search and return to the type-based view.
The REST Endpoint Link
In the top right corner of the content area, a link to the REST endpoint for the current type is displayed.
HTML REST View
When you access a REST URL with a browser, Structr detects the text/html content type and returns a formatted HTML page instead of raw JSON. Objects appear with collapsible JSON structures that you can expand and navigate. A status bar at the top lets you switch between the available views for the type.
This feature makes it easy to explore your data and debug API responses directly in the browser, without needing external tools like Postman or curl.
Pages
The Pages area is the visual editor for building your application’s user interface. It combines a page tree, property panels, and live preview in one workspace. Here you design layouts, configure data bindings, set up interactions, and preview the results.
The Workspace
The screen is divided into three parts: a left sidebar with the page tree and localization tools, a main area for properties and preview, and a right sidebar with widgets, shared components, recycle bin, and preview panel. All sidebars are collapsible, so you can expand your workspace when you need more room.
Left Sidebar
The Page Tree
The Pages panel shows all your pages as expandable trees. Each page reveals its structure when expanded: HTML elements, templates, content nodes, and their nesting relationships.
Element Icons
Different element types have distinct icons:
- Window icon – Page elements
- Box icon – HTML elements
- Colored box (red, green, yellow) – Repeater elements
- Application icon – Template elements
- Document icon – Content elements (these cannot be expanded because they have no children)
Visibility Indicators
A lock icon on the right of each element indicates its visibility settings:
- No icon – The element is visible to both public and authenticated users
- Lock with key – Only one visibility flag is enabled
Interaction
Click an element to select it and view its properties in the main area. Right-click (or hover and click the menu icon) to open the context menu. Drag elements to reorder them or move them between parents.
Localization
The Localization panel lets you manage translations for the current page. Select a page, enter a language code, and click refresh to see all localize() calls used in that page. You can create, edit, and delete translations directly here.
Right Sidebar
Widgets
The Widgets panel contains reusable page fragments. You can drag a widget onto your page tree to insert it. If the widget has configuration options, a dialog appears where you can enter values before insertion.
Suggested Widgets
Widgets can also appear as suggestions in the context menu when their selector matches the element you’ve right-clicked. This speeds up common patterns.
Local and Remote Widgets
The panel shows both local widgets (stored in your database) and remote widgets (fetched from configured servers). Click the plus button to create new local widgets.
Shared Components
Shared components work differently from widgets. When you insert a widget, Structr copies its content into your page. When you insert a shared component, Structr creates a reference to the original. If you edit the shared component, every page that uses it updates automatically.
You can create a shared component by dragging an element from the page tree into the Shared Components panel. Headers, footers, and navigation menus are ideal candidates – anything that should look and behave the same across multiple pages.
Recycle Bin
When you delete an element from a page, it goes to the recycle bin rather than being permanently removed. You can drag elements back into the page tree to restore them. This safety net is especially valuable when restructuring complex pages.
Note that pages themselves are not soft-deleted. When you delete a page, only its child elements go to the recycle bin.
Preview
The Preview panel shows your page as users will see it. You can keep the preview visible while working with other tabs in the main area, watching your changes take effect in real time.
Editing Elements
When you select an element in the page tree, the main area shows its properties organized in tabs. The available tabs depend on the element type.
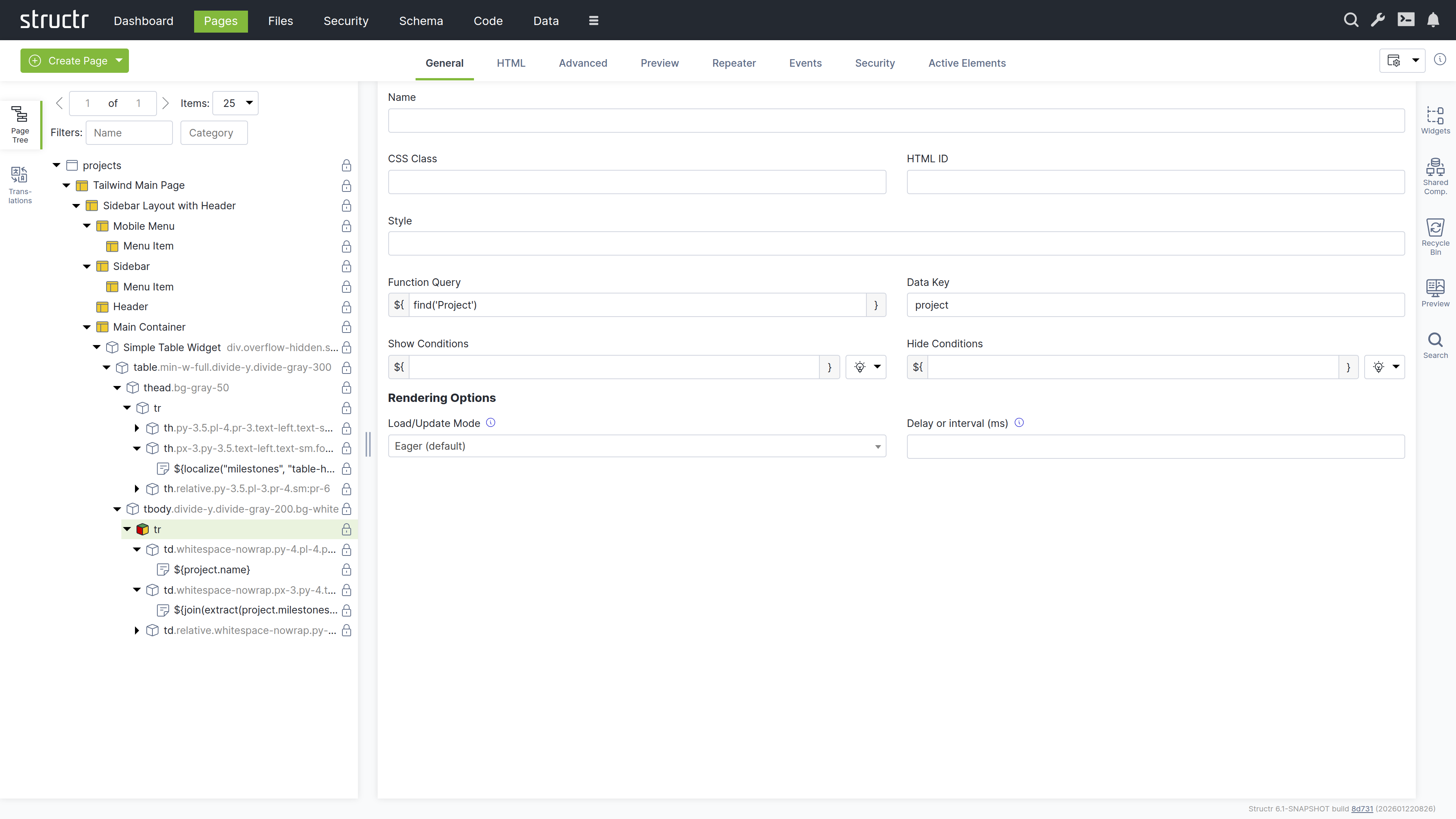
General Tab
This contains basic settings: name, CSS classes, HTML ID, and inline styles. For repeaters, the Function Query and Data Key fields are located here. Show and Hide Conditions control whether the element appears in the output.
HTML Tab
This is available for HTML elements. Here you can manage HTML attributes – both global attributes and tag-specific ones. Click “Show all attributes” to reveal event handlers like onclick. You can add custom attributes with the plus button.
Editor Tab
This is available for templates and content elements. It provides a Monaco-based code editor with syntax highlighting and autocompletion. The content type selector at the bottom controls processing: Markdown and AsciiDoc convert to HTML, while plaintext, XML, and JSON output directly.
Repeater Tab
Here you can configure data-driven rendering. Select a source (Flow, Cypher Query, or Function Query), define the data key, and the element renders once for each object in the result.
Events Tab
Here you can set up Event Action Mappings – what happens when users interact with the element. Select a DOM event, choose an action, configure parameters, and define follow-up behaviors.
Security Tab
This shows access control settings: owner, visibility flags, and individual permissions.
Advanced Tab
This provides a raw view of all attributes in an editable table. It is useful for properties that are not exposed in other tabs.
Preview Tab
This shows the rendered page. Hover over elements to highlight them in both the preview and the tree. Click to select for editing.
Active Elements Tab
This gives you an overview of key components: templates, repeaters, and elements with event action mappings. Click any item to jump to its location in the tree.
URL Routing Tab
This is available for pages. Here you can configure additional URL paths with typed parameters. See the Navigation & Routing chapter for details.
The Context Menu
Right-click any element to open the context menu. What you see depends on the element type.
Insert Options
These let you add new elements as children or siblings. Suggested Widgets appear when widgets match the current element’s selector. Suggested Elements offer common children for the current tag (for example, <tr> for tables, <li> for lists).
Edit Options
- Clone – Copies the element and inserts it after the original
- Wrap Element In – Wraps the element with a new parent
- Replace Element With – Swaps the element while keeping its children
- Convert to Shared Component – Moves the element to shared components
Select/Deselect
This marks elements for move or clone operations. After selecting, you can right-click elsewhere and choose “Clone Selected Element Here” or “Move Selected Element Here.”
Remove Node
This sends the element to the recycle bin.
Creating Pages
The Create Page button in the secondary menu offers two options:
Create
Opens a dialog with templates based on Tailwind CSS, ranging from empty pages to complex layouts with sidebars and navigation. These templates are actually widgets with the “Is Page Template” flag enabled.
Import
Lets you create pages from HTML source code or by fetching from an external URL. This is how you bring existing designs into Structr and make them dynamic.
Related Topics
- Pages & Templates – Explains how to build page structures, work with templates, and create widgets and shared components
- Dynamic Content – Covers data binding, template expressions, and repeaters
- Event Action Mapping – Details how to handle user interactions
- Navigation & Routing – Describes URL configuration and the
currentkeyword - Security – Explains visibility flags and access control
Security
The Security area is where you manage access control for your application. Here you create users and organize them into groups, define which REST endpoints are accessible to authenticated and anonymous users, and configure cross-origin request settings for browser-based clients. The permission model supports both role-based access through groups and fine-grained object-level permissions. Each of these concerns has its own tab.
Users and Groups
The first tab displays two lists side by side: users on the left, groups on the right. Both lists are paginated and filterable, which is helpful when you have many users.
Creating Users and Groups
Click the Create button above either list to add a new user or group. If you’ve extended the User or Group types (by creating subclasses or adding the User trait to another type), a dropdown appears next to the button that lets you choose which type to create.
Organizing Your Security Model
You can drag users onto groups to make them members, and drag groups onto other groups to create hierarchies. This flexibility lets you model complex organizational structures: departments containing teams, teams containing members, with permissions flowing through the hierarchy.
Editing Users
Click a user to edit the name inline. For more options, hover over the user and click the menu icon to open the context menu.
General Dialog
Here you can edit essential user properties: name, password, and email address. Three flags control special behaviors:
- Is Admin User – Grants full access, bypassing all permission checks
- Skip Security Relationships – Optimizes performance for users who do not need fine-grained permissions
- Enable Two-Factor Authentication – Adds an extra security layer for this user
The Failed Login Attempts counter (useful for diagnosing lockouts) and the Confirmation Key (used during self-registration) are also available here.
Advanced Dialog
This shows all user attributes in a raw table format.
Security Dialog
This opens the access control dialog for the user object itself.
Delete User
This removes the account.
See the User Management chapter for detailed explanations of these settings.
Editing Groups
Groups have names and members but fewer special properties. Click to edit the name inline. Use the context menu to access the Advanced dialog (all attributes), Security dialog (access control for the group object), or Delete Group.
Resource Access
The second tab controls which REST endpoints are accessible and to whom.
The Resource Access Table
Each row represents a grant with:
- Signature – The URL pattern this grant applies to
- Permissions – Checkboxes for each HTTP method (GET, POST, PUT, DELETE, OPTIONS, HEAD, PATCH), separately for authenticated and non-authenticated users
Creating Grants
Enter a signature in the input field next to the Create button and click Create. For details on signature syntax and configuration patterns, see the User Management chapter.
Per-User and Per-Group Grants
Resource Access grants are themselves objects with their own access control. Click the lock icon at the end of any row to open the access control dialog for that grant.
This means you can create multiple grants for the same signature, each visible to different users or groups. One grant might allow read-only access for regular users, while another allows full access for administrators. Each user sees only the grants that apply to them.
Visibility Options
The Settings menu on the right side of the tab bar includes options for showing visibility flags and bitmask columns in the table. The bitmask is a numeric representation of the permission flags, which can be useful for debugging.
CORS
The third tab configures Cross-Origin Resource Sharing settings.
The CORS Table
Each row configures CORS for one URL path. Enter a path in the input field, click Create, then fill in the columns:
Accepted Origins
This specifies which domains can make requests. Use * to allow any origin, or list specific domains like https://example.com. This becomes the Access-Control-Allow-Origin header.
Max Age
This tells browsers how long to cache the CORS preflight response, in seconds. Higher values reduce preflight requests but delay the effect of configuration changes.
Allow Methods
This lists which HTTP methods are permitted: GET, POST, PUT, DELETE, etc.
Allow Headers
This specifies which request headers clients can send: Content-Type, Authorization, etc.
Allow Credentials
This controls whether browsers include cookies and HTTP authentication with cross-origin requests.
Expose Headers
This determines which response headers JavaScript can access. By default, only a few headers are exposed; list additional ones here.
The delete button is in the second column.
For details on CORS concepts and configuration patterns, see the Authentication chapter in REST Interface.
Related Topics
- User Management – Concepts behind users, groups, and permissions
- REST Interface/Authentication – Resource Access Permissions and CORS
Code
The Code area is where you write and organize your application’s business logic. While the Schema area gives you a visual overview of types and relationships, the Code area focuses on what those types actually do – their methods, computed properties, and API configuration.
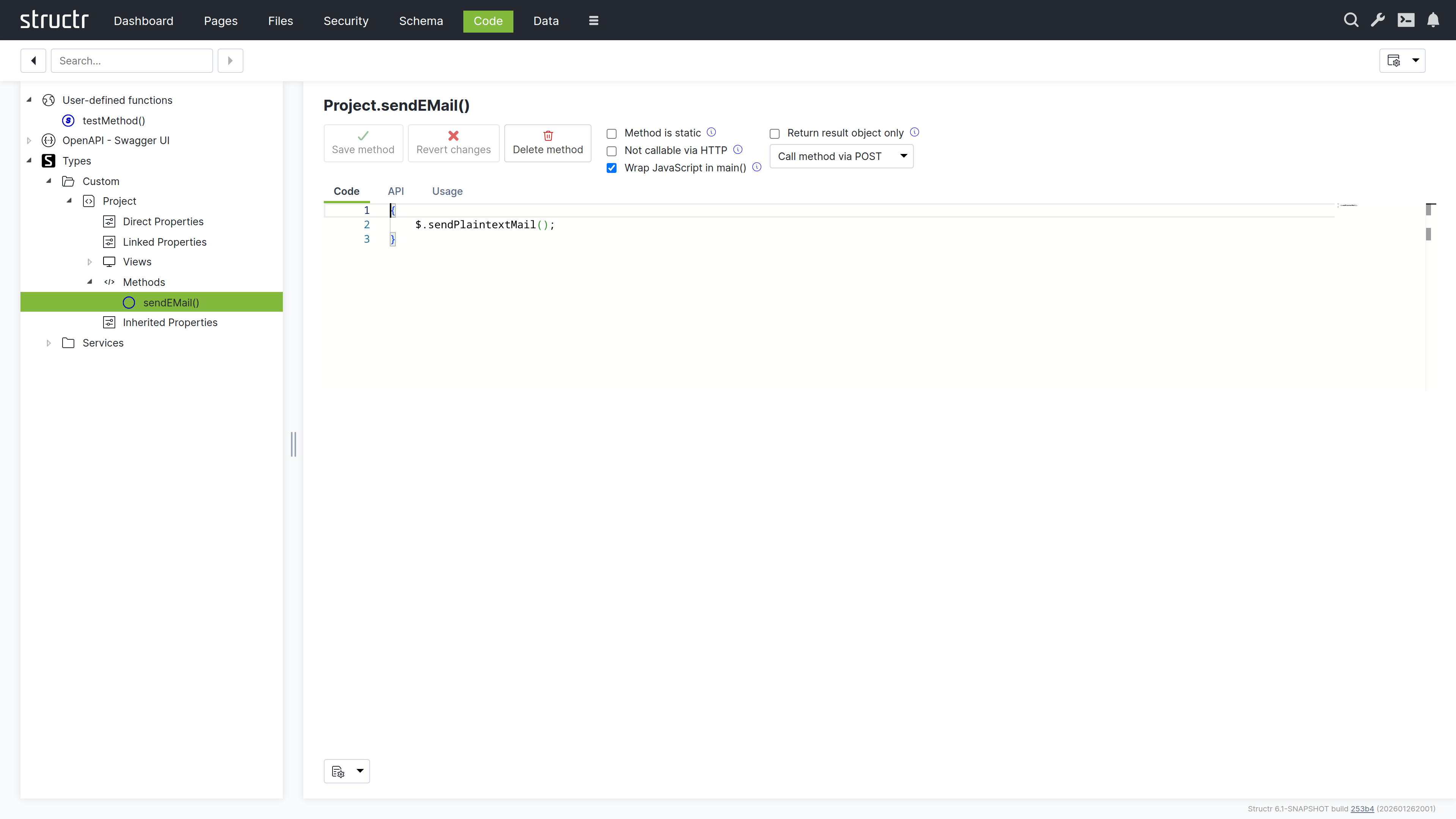
Working with the Code Area
The screen is divided into a navigation tree on the left and a context-sensitive editor on the right. The tree organizes your code by type: expand a type to see its properties, views, and methods. Click any item to edit it.
Here you also have access to user-defined functions (global utilities available throughout your application) and service classes (containers for business logic that does not belong to a specific type). The OpenAPI output is also available here, which is useful for verifying how your methods appear to API consumers.
The Navigation Tree
The tree contains the following sections:
User Defined Functions
This shows global functions in a table format – the same view that is available in the Schema area. These functions are callable from anywhere in your application.
OpenAPI
This section displays the OpenAPI specification for your application. The specification is also exposed as a public endpoint that external consumers can access to discover and interact with your APIs. It serves as the authoritative reference for all API endpoints defined in your application, documenting available methods, their parameters, and expected responses.
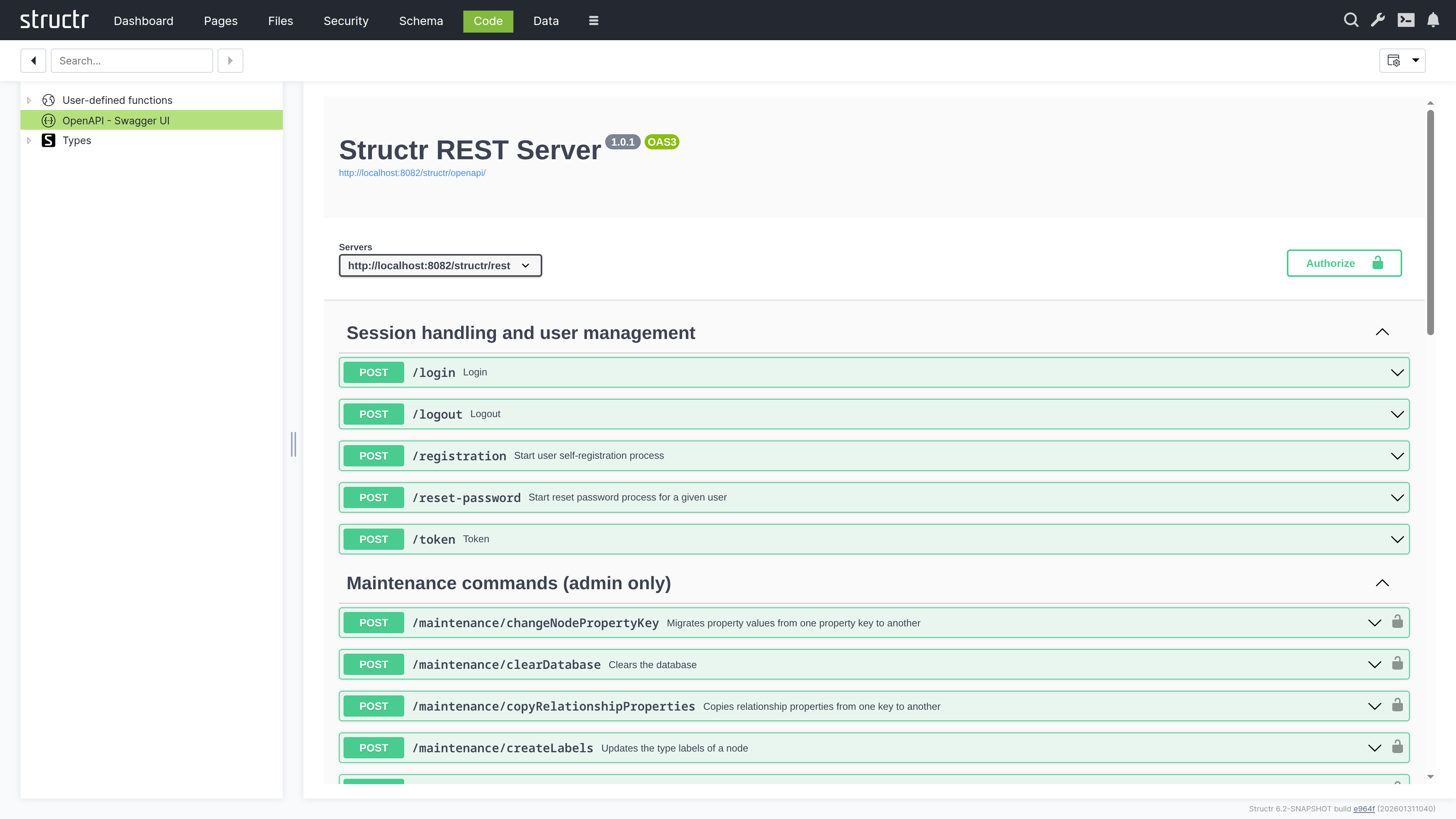
Types
This lists all your custom types and service classes. Expand a type to see its contents:
- Direct Properties – Properties defined on this type
- Linked Properties – Properties from relationships
- Views – Property sets for different contexts (API responses, UI display)
- Methods – The business logic attached to this type
- Inherited Properties – Properties from parent types or traits
This structure mirrors what you see in the Schema type editor, but it is organized for code navigation rather than visual modeling.
Services
This is a category under Types for service classes. Service classes can only contain methods, not properties. They are useful for grouping related business logic that does not belong to a specific data type – things like report generators, external integrations, or utility functions.
The Method Editor
Click any method to open the editor.
Writing Code
The editor is based on Monaco (the same engine as VS Code), with syntax highlighting for JavaScript and StructrScript, autocompletion, and all the features you would expect from a modern code editor.
At the bottom of the screen, a settings dropdown lets you configure the editor to your preferences: word wrap, indentation style, tab size, code folding, and more.
Method Configuration
Above the editor, several options control how the method behaves:
Method is static
This means the method can be called without an object instance – it is a class-level function rather than an instance method.
Not callable via HTTP
This hides the method from the REST API. Use it for internal utilities that should not be exposed.
Wrap JavaScript in main
This wraps your code in a main function, which affects scoping and is sometimes needed for compatibility.
Return result object only
This strips metadata from the response, returning just the result.
HTTP verb dropdown
This specifies which HTTP method triggers this function when called via REST API: GET for read operations, POST for creating things, PUT for updates, DELETE for removals.
Testing Your Code
For static methods, a Run Dialog button appears in the action bar alongside Save, Revert, and Delete. Click it to open a testing interface where you can enter parameters and execute the method immediately. The return value displays in the dialog, making it easy to test and debug without leaving the editor.
API Tab
Here you can define typed parameters for your method. Structr validates incoming requests against these definitions before your code runs, catching type mismatches and missing required parameters automatically. This also generates OpenAPI documentation.
Usage Tab
This shows how to call the method from different contexts: JavaScript, StructrScript, and REST API. The examples use your actual method name and parameters, so you can copy them directly into your code.
Searching Your Code
The search field in the secondary menu searches across all code in your application – schema methods, user-defined functions, and service classes. This is invaluable when you need to find where something is defined or used.
Note that the search does not include page content. For that, use the Pages area.
Two Views, One Model
The Code area and Schema area are two perspectives on the same underlying data. Changes you make in one immediately appear in the other.
Use the Schema area when you are thinking about structure – what types exist, how they relate to each other, what properties they have. Use the Code area when you are thinking about behavior – what methods do, how they are implemented, how they are called.
Files
The Files area is Structr’s virtual file system – a familiar file browser interface where you can manage your application’s static assets. CSS, JavaScript, images, documents, and any other files live here.
Secondary Menu
Create Folder
Creates a new folder in the currently selected directory. If you’ve created types that extend Folder, a dropdown lets you choose which type to create.
Create File
Creates a new empty file in the current directory. Like with folders, a dropdown appears if you have custom file types.
Mount Folder
Opens the Mount Dialog for connecting external storage locations to Structr’s virtual file system.
The Mount Dialog
Mounting lets you integrate external directories or storage providers into Structr. When you mount a folder, Structr monitors it for changes and automatically updates metadata when files are added or modified.
The dialog includes:
- Storage Provider dropdown – Select the storage backend (currently local file system; S3 and others may be available through modules)
- Folder name – The name for the new mounted folder in Structr
- Mount target – The path or location to mount
- Scan settings – Configure how Structr detects changes: either through file system events (Unix-based systems only) or periodic scanning with a configurable interval
Search
The search field on the right searches across all files, including their contents. This full-text search is powered by Apache Tika and can index text from PDFs, images (via OCR), Office documents, and many other formats. Type your query and press Enter to see results.
Left Sidebar
Favorites
At the top of the directory tree, Favorite Files provides quick access to frequently used files. Drag any file here during development to keep it handy – this is useful for JavaScript files, stylesheets, or configuration files you edit often.
Directory Tree
Below Favorites, the familiar folder hierarchy shows your file system structure. Click a folder to view its contents on the right. Click a file or folder name to rename it inline.
Main Area
The main area shows the contents of the selected folder.
View Controls
At the top right, three buttons switch between view modes:
- List – Compact rows with detailed information
- Tiles – Medium-sized previews with thumbnails
- Images – Larger previews, ideal for browsing image folders
A pager on the left handles large directories, and a filter box lets you narrow down the displayed files.
The File Table
In list view, each row shows:
- Icon – Click to download or open the file (depending on content type)
- Name – The file name
- Lock icon – Opens the Access Control dialog
- Export checkbox – Marks the file for inclusion in deployment exports (only available below the top level)
- UUID – The file’s unique identifier
- Modified – Last modification timestamp
- Size – File size
- Type – Both the Structr type and MIME type
- Owner – The file’s owner
Hold Ctrl while clicking to select multiple files for bulk operations.
Uploading Files
Drag files from your desktop onto the right side of the Files area to upload them. Files are Base64-encoded and uploaded in chunks via WebSocket. This works well for smaller files; for large files or bulk uploads, consider using the REST API or deployment import.
Search Results
When you search, results appear in a table similar to the file list. A magnifying glass icon at the start of each row shows the search context – click it to see where your search term appears within the file.
Context Menu
Right-click a file or hover and click the menu icon to open the context menu.
Edit File
Opens the file in a built-in editor. The editor warns you before opening binary files or files that are too large. For text files, you get syntax highlighting based on the file type.
If the file has the isTemplate flag enabled, a checkbox in the editor lets you preview the rendered output with template expressions evaluated.
General
Opens the file’s property dialog with:
- Name – The file name
- Content Type – The MIME type (affects how browsers handle the file)
- Cache for Seconds – Controls HTTP cache headers when serving the file
- isTemplate – When enabled, Structr evaluates template expressions in the file content before serving it, allowing you to mix static and dynamic content
- Caching disabled – Prevents browser caching
- Include in Frontend Export – Marks the file for deployment export
Advanced
The raw attribute table, same as in other areas.
Add to Favorites
Adds the file to the Favorites section for quick access.
Copy Download URL
Copies the file’s download URL to your clipboard.
Download File
Downloads the file directly.
Security
A submenu with:
- Access Control / Visibility – Opens the full access control dialog
- Quick toggles – Make the file visible to authenticated users, public users, or both
Delete File
Removes the file. When multiple files are selected, this becomes “Delete Files” and removes all selected items.
Folder Context Menu
Folders have a simpler context menu with General (just name and export checkbox), Advanced, Security, and Delete Folder.
Content Type Features
Some content types unlock additional functionality.
CSV and XML Files
Files with text/csv or text/xml content type show an “Import CSV” or “Import XML” menu entry that opens the import wizard documented in the Importing Data chapter.
ZIP Archives
ZIP files show two additional options:
- Extract Archive Here – Extracts contents into the current folder
- Extract Archive to New Folder – Creates a new folder and extracts there
Images
Images get special treatment:
Automatic Thumbnails
Structr generates thumbnails on first access, stored in a hidden ._structr_thumbnails folder. Two thumbnail sizes are created automatically and linked to the original image via database relationships.
Metadata Extraction
EXIF data like camera settings, GPS coordinates, and timestamps are automatically extracted and stored as properties. Width and height are also read and stored.
Edit Image
Opens a simple editor for cropping images.
Checksums
Structr automatically calculates checksums for all files. By default, a fast xxHash is computed; you can configure additional algorithms in structr.conf.
Naming Conflicts
If you create a file with a name that already exists in the folder, Structr automatically appends a timestamp to make the name unique.
Related Topics
- Importing Data – CSV and XML import wizards
- Data Model – Creating custom file types with the File trait
- Security – File permissions and visibility
- Pages & Templates – Using files in pages, the isTemplate feature
Graph
The Graph area is an interactive graph explorer where you can visualize your data objects and their relationships. This area is particularly useful when you need to understand the connections between objects in your database, explore how data is interlinked, or navigate complex relationship structures. By starting from a query result, you can progressively expand the visualization to discover related objects step by step. By default, this area is hidden in the burger menu.
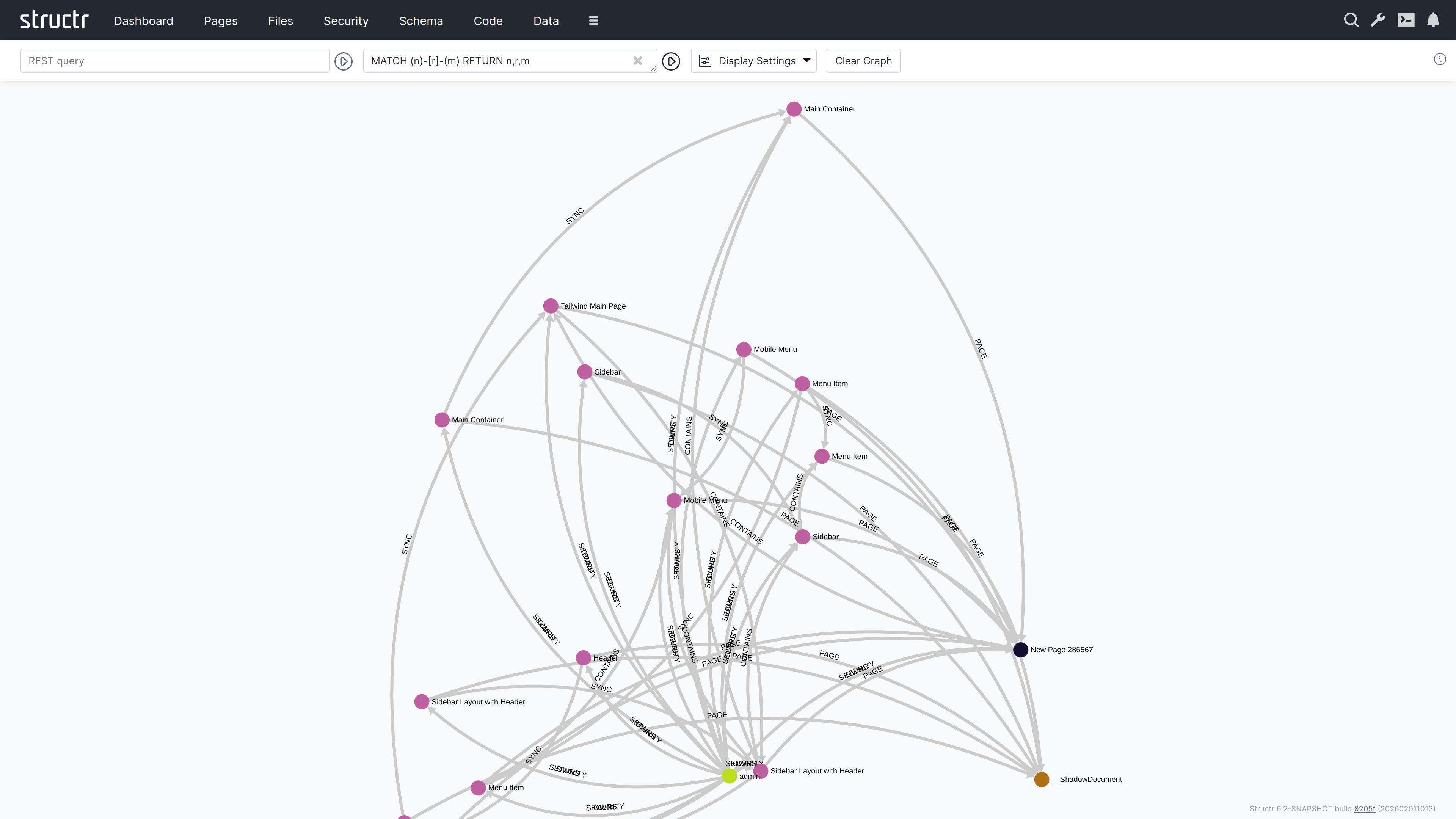
Querying Data
The header contains two input fields for specifying which data to display.
REST URL
In the left input field, you can enter a REST URL to load objects. The results will be displayed as nodes in the graph visualization.
Cypher Query
In the right input field, you can enter a Cypher query to further filter or transform the results.
The Graph Visualization
Each object returned by your query appears as a filled circle on the canvas, with its name displayed as a label.
Exploring Relationships
When you hover over a node, additional colored circles appear around it. Each colored circle contains a number indicating how many outgoing relationships of a particular type exist. The colors distinguish different relationship types.
Click on one of these colored circles to follow all relationships of that type. The related nodes are then added to the visualization, and you can see the connections between them. This way, you can progressively navigate through your data graph, expanding the view step by step.
Display Options
A dropdown menu next to the input fields provides configuration options:
Display Options
Two checkboxes control what’s shown in the visualization:
- Node Labels – Shows or hides the names on nodes
- Edge Labels – Shows or hides the names on relationship lines
Layout Algorithm
You can choose between two different layout algorithms that determine how nodes are arranged on the canvas.
Clear Graph
This button resets the visualization, removing all displayed nodes and relationships so you can start fresh.
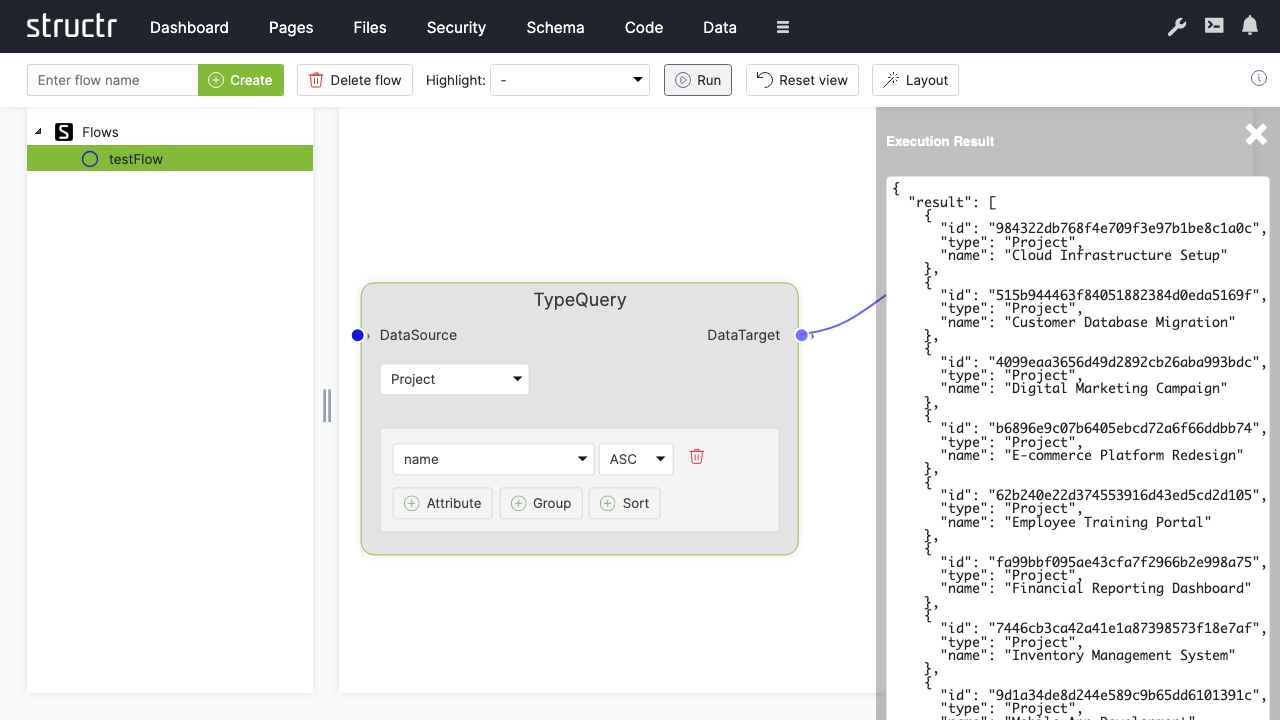
Flows
The Flows area is a visual workflow designer where you can create automated processes using flow-based programming. This approach is similar to visual scripting tools like Unity’s Visual Script. By default, this area is hidden in the burger menu.
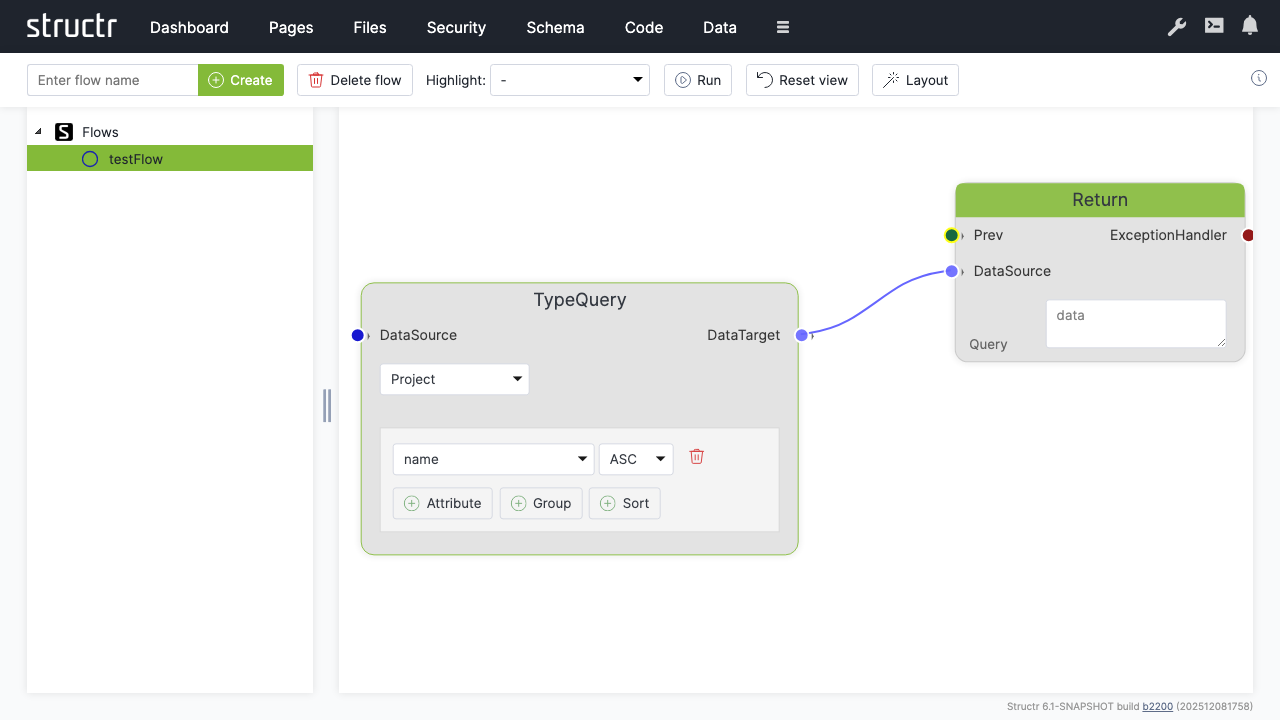
Secondary Menu
Create Flow
An input field and Create button on the left let you create a new flow. A flow is a container for flow nodes that you connect to define a process.
Delete
Deletes the currently selected flow.
Highlight
A dropdown that highlights different aspects of your flow: Execution, Data, Logic, or Exception Handling. This helps you focus on specific channels when working with complex flows.
Run
Executes the current flow.
Reset View
Resets the canvas zoom and pan position.
Layout
Automatically arranges the flow nodes on the canvas.
Left Sidebar
The sidebar shows a tree of all flows in your application. Click on a flow to open it on the canvas.
The Canvas
The main area displays the flow nodes and their connections. You can zoom and pan the canvas to navigate larger flows.
Adding Nodes
Right-click on the canvas to open the context menu, which lets you add new nodes. The menu is organized into categories:
Action Nodes
Action, Call for each, Aggregate, Filter, Exception Handler, Log, Return
Data Nodes
Datasource, Constant, CollectionDatasource, ObjectDatasource, KeyValue, ParameterInput, ParameterDataSource, Store, GetProperty, First, TypeQuery
Logic Nodes
Decision, Not Null, Not Empty, Not, Or, And, Is True, Comparison, Script Condition, Switch, Switch Case
Actions
Execute Flow, Reset View, Select and Apply Layout
Connecting Nodes
Each node has input and output connectors. You connect nodes by dragging from an output connector to an input connector. The connectors are color-coded by channel type:
- Green – Execution channel (controls the order of operations)
- Blue – Data channel (passes data between nodes)
- Red – Exception handling channel (handles errors)
- Dark green – Logic channel (passes boolean values)
You can only connect connectors of the same type.
Related Topics
- Flows – Detailed documentation on flow-based programming, node types, and building workflows
Job Queue
The Job Queue area displays scheduled jobs and background tasks. Despite its current label “Importer” in the UI, this area is not limited to import operations – it shows all jobs created with the $.schedule() function as well as batch import jobs. By default, this area is hidden in the burger menu.
Note: This area will be renamed from “Importer” to “Job Queue” in a future release.
Secondary Menu
Refresh
The button on the left refreshes the job list.
Cancel Jobs
An input field labeled “Cancel all queued jobs after this ID” lets you specify a job ID. Click the Cancel Jobs button to cancel all queued jobs with IDs higher than the specified value. This is useful when you need to stop a large number of scheduled jobs at once.
Settings
On the right side, the usual configuration options are available.
The Job Table
The main area displays a table of all jobs with the following columns:
- Job ID – The unique identifier for the job
- Job Type – The type of job (e.g., scheduled function, import batch)
- User – The user who created the job
- File UUID – For import jobs, the UUID of the file being imported
- File Path – For import jobs, the path to the file
- File Size – For import jobs, the size of the file
- Processed Chunks – For chunked imports, shows progress as processed/total chunks
- Status – The current state of the job (queued, running, completed, failed)
- Action – Actions you can perform on the job, such as cancelling it
Background
This area was originally designed to display import jobs – when you import a large file that gets split into chunks, each batch appears here so you can monitor progress. Later, the area was extended to also show jobs created with the $.schedule() function, making it a general-purpose job monitor.
Related Topics
- Importing Data – Details on CSV and XML import processes
- Business Logic – Using
$.schedule()to create background jobs
Localization
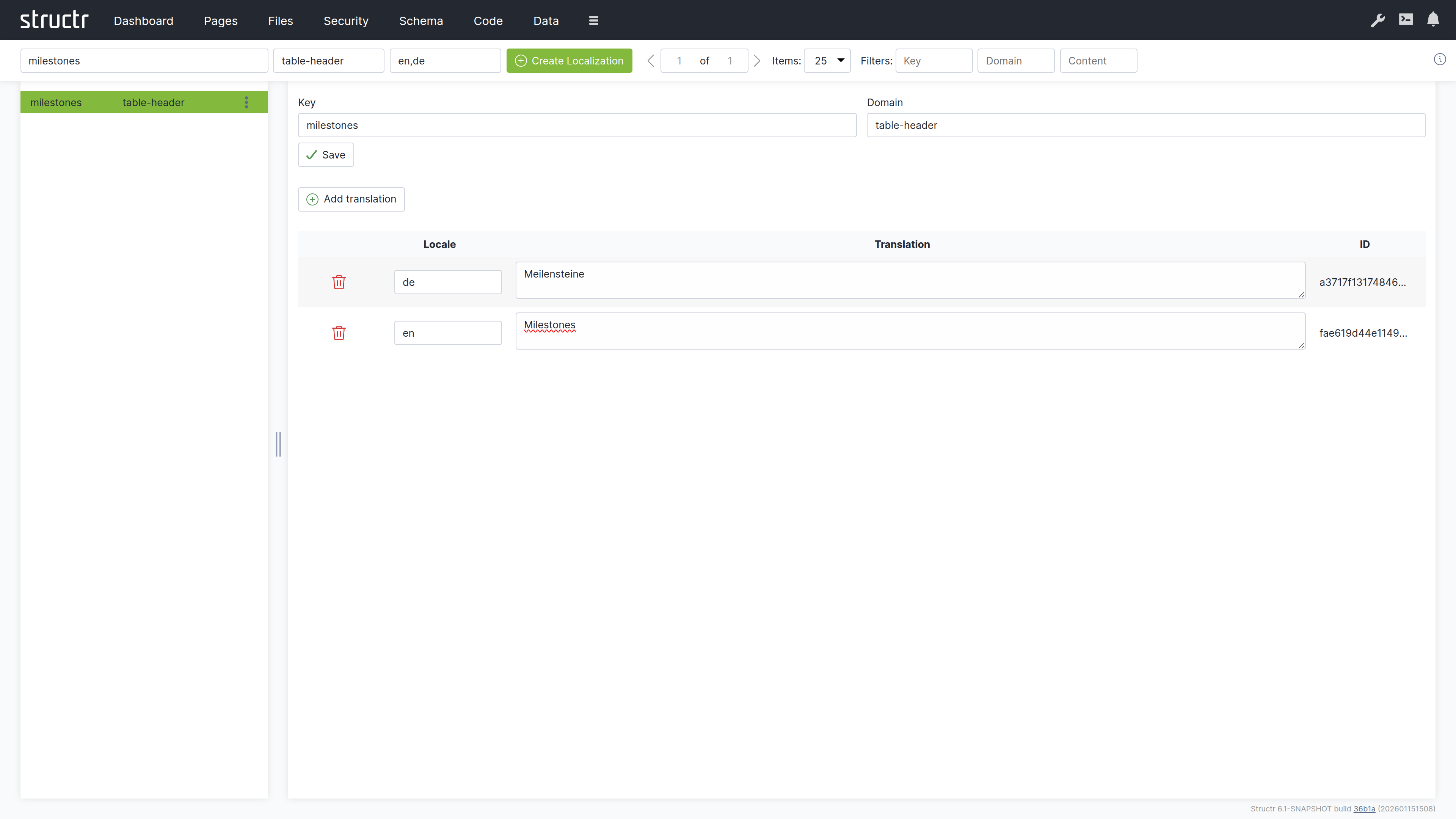
The Localization area is where you manage translations for multi-language applications. Here you create and edit the translation entries that the localize() function looks up when rendering pages. Each entry consists of a key, an optional domain for organizing related translations, and one or more locale-specific translations. When a page calls localize() with a key, Structr returns the appropriate translation based on the current user’s locale setting. By default, this area is hidden in the burger menu.
Note: This area appears empty until you create your first localization entry.
Secondary Menu
Create Localization
Three input fields let you create a new localization entry by entering Key, Domain (optional), and Locale. Click the Create Localization button to create it. After creation, select the entry in the list to add the actual translated text.
Pager
Navigation controls for browsing through large numbers of entries.
Filter
Three input fields let you filter the list by Key, Domain, and Content.
Left Sidebar
The sidebar lists all localization entries. Each entry shows its key, and entries with the same key but different locales are grouped together. Click an entry to select it and edit its translations in the main area.
The context menu on each entry provides Edit (opens the properties dialog) and Delete options.
Main Area
When you select a localization entry, the main area shows an editor for that key and all its translations across different locales.
Key and Domain
Two input fields at the top let you edit the key name and domain. Changing the key here updates all translations that share this key.
Save Button
Saves changes to the key and domain fields.
Add Translation Button
Adds a new translation row for an additional locale.
Translations Table
The table shows all translations for the selected key:
| Column | Description |
|---|---|
| (Actions) | Delete and Save buttons for each translation |
| Locale | The language code – edit directly to change |
| Translation | The translated text – edit directly to change |
| ID | The unique identifier (read-only) |
You edit the Locale and Translation fields directly in the table. Click Save on the row to persist your changes.
Related Topics
- Pages & Templates – The Translations section explains the
localize()function, locale resolution, and the Translations flyout
Virtual Types
The Virtual Types area is where you create and configure virtual types – dynamic data transformations that expose transformed data via REST endpoints. Virtual types allow you to present your data in different formats without modifying the underlying schema. You can rename properties, filter objects, apply transformations, and create simplified views of complex data structures. This makes them useful for building APIs that present data differently to different consumers, or for transforming data during import and export operations. By default, this area is hidden in the burger menu.
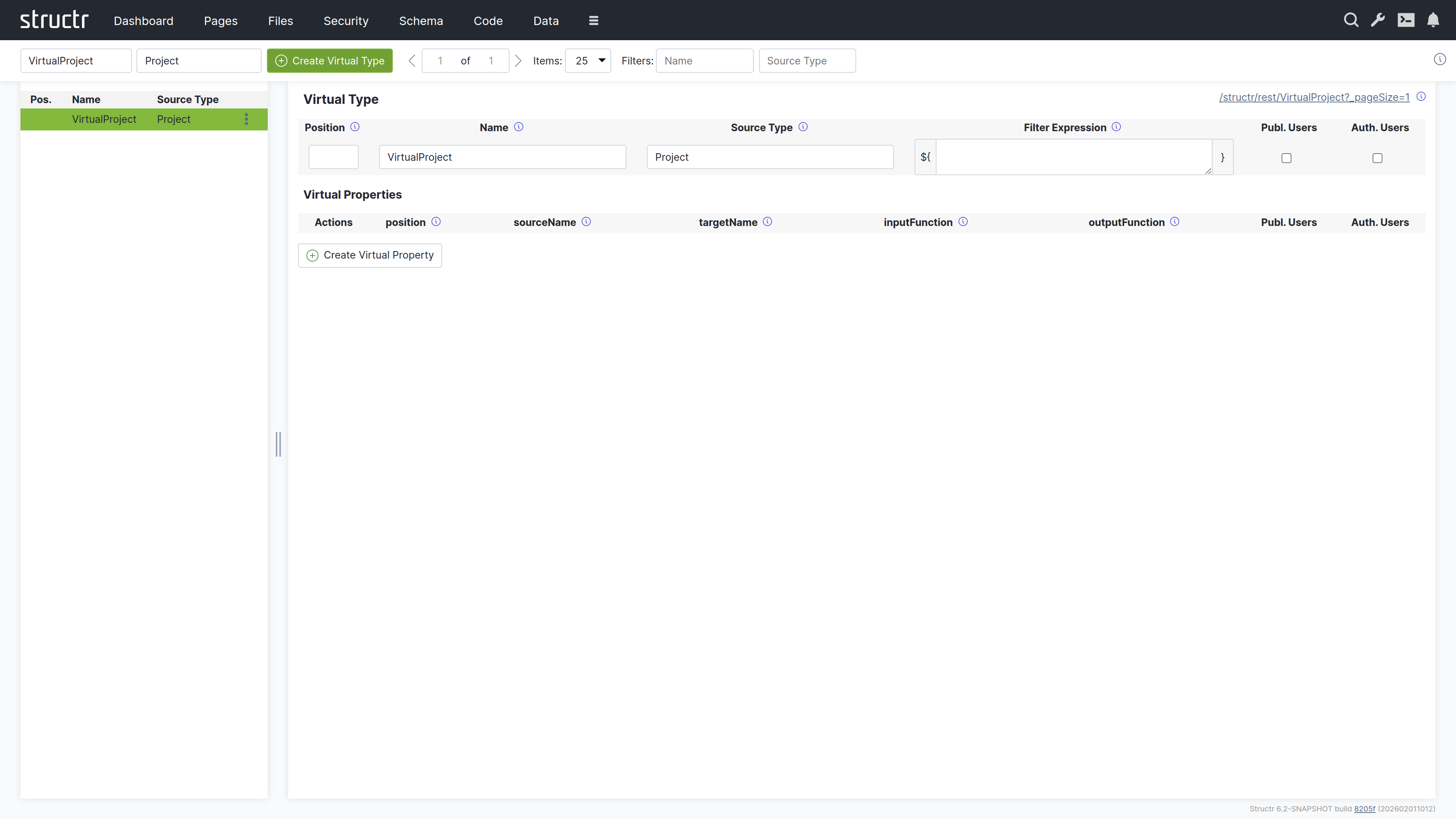
Note: This area appears empty until you create your first virtual type.
Secondary Menu
Create Virtual Type
On the left, two input fields let you enter the Name and Source Type for a new virtual type. Both fields are required. Click the Create button to create it.
Pager
Navigation controls for browsing through large numbers of virtual types.
Filter
Two input fields on the right let you filter the list by Name and Source Type.
Left Sidebar
The sidebar shows a list of all virtual types with the following information:
- Position – The sort order
- Name – The virtual type name
- Source Type – The type that provides the source data
Each entry has a context menu with Edit and Delete options.
Main Area
When you select a virtual type, the main area shows an editor for its configuration. In the top right corner, a link to the REST endpoint for this virtual type is displayed (as an HTML view, same as in the Data area).
Virtual Type Settings
The upper section contains settings for the virtual type itself:
- Position – Controls the sort order in the list
- Name – The name of the virtual type (also determines the REST endpoint URL)
- Source Type – The type that provides the source data
- Filter Expression – An optional script expression that filters which source objects are included
- Visible to Public Users – Checkbox for public visibility
- Visible to Authenticated Users – Checkbox for authenticated user visibility
Virtual Properties Table
Below the settings, a table shows all virtual properties defined for this type. The columns are:
- Actions – Edit and delete buttons
- Position – Sort order of the property
- Source Name – The property name on the source type
- Target Name – The property name in the virtual type output
- Input Function – Optional transformation script for input (used during imports)
- Output Function – Optional transformation script for output
- Public Users – Visibility flag
- Authenticated Users – Visibility flag
Create Virtual Property
A button below the table lets you add new virtual properties.
Related Topics
- Virtual Types – Detailed documentation on data transformation concepts, use cases, and scripting
- Importing Data – Using virtual types for CSV import transformations
- REST Interface – How virtual types create REST endpoints
Mail Templates
The Mail Templates area is where you create and manage email templates for your application. These templates define the content and structure of automated emails such as registration confirmations, password resets, or notification messages. Templates can include template expressions that are replaced with dynamic content when the email is sent, allowing you to personalize messages with user-specific information. Each template can have multiple locale variants to support multi-language applications. By default, this area is hidden in the burger menu.
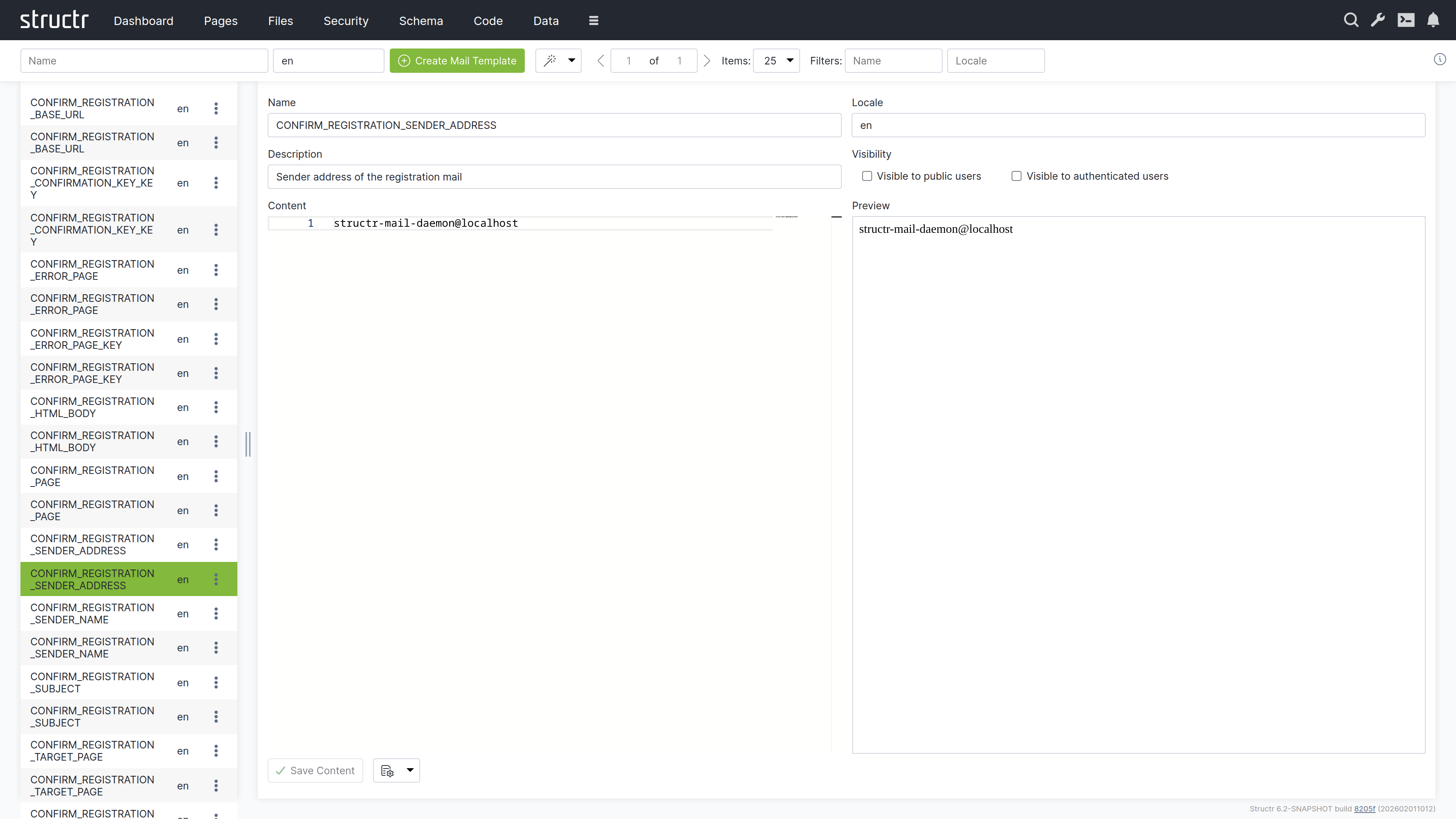
Note: This area appears empty until you create your first mail template.
Secondary Menu
Create Mail Template
On the left, two input fields let you enter the Name and Locale for a new mail template. Click the Create button to create it.
Template Wizard
The wand button labeled “Create Mail Templates for Processes” opens a wizard that automatically generates mail templates for common workflows:
- User Self-Registration – Templates for the registration confirmation email
- Reset Password – Templates for the password reset email
This saves time when setting up standard authentication workflows.
Pager
Navigation controls for browsing through large numbers of mail templates.
Filter
Two input fields on the right let you filter the list by Name and Locale.
Left Sidebar
The sidebar shows a list of all mail templates. Click on a template to open it in the editor on the right.
Each entry has a context menu with:
- Properties – Opens the Advanced dialog for the mail template, which also includes the Security section
- Delete – Removes the template
Main Area
When you select a mail template, the main area shows an editor with the following sections:
Template Settings
The upper section contains:
- Name – The template name (used to reference the template in code)
- Locale – The language/locale code for this template
- Description – An optional description of the template’s purpose
- Visible to Public Users – Visibility checkbox
- Visible to Authenticated Users – Visibility checkbox
Content Editor
On the left side, a text editor lets you write the email content. You can use template expressions with the ${...} syntax to insert dynamic values that are replaced when the email is sent.
Preview
On the right side, a preview panel shows how the template will look.
Related Topics
- SMTP – Configuring email sending
- User Management – User self-registration and password reset workflows that use mail templates
Configuration Interface
The Configuration Interface provides access to all runtime settings that control Structr’s behavior. You can open it by clicking the wrench icon in the header bar. The interface opens in a new browser tab and requires a separate login using the superuser password defined in structr.conf.
This separation is intentional. The Configuration Interface provides access to sensitive operations that go beyond normal application administration: you can configure database connections, restart services, and define cron expressions for scheduled functions. These capabilities would otherwise require direct access to maintenance commands or configuration files. By requiring a separate authentication with the superuser password, Structr adds an additional layer of security that protects these critical settings even if an attacker gains access to a regular admin account.
Interface Layout
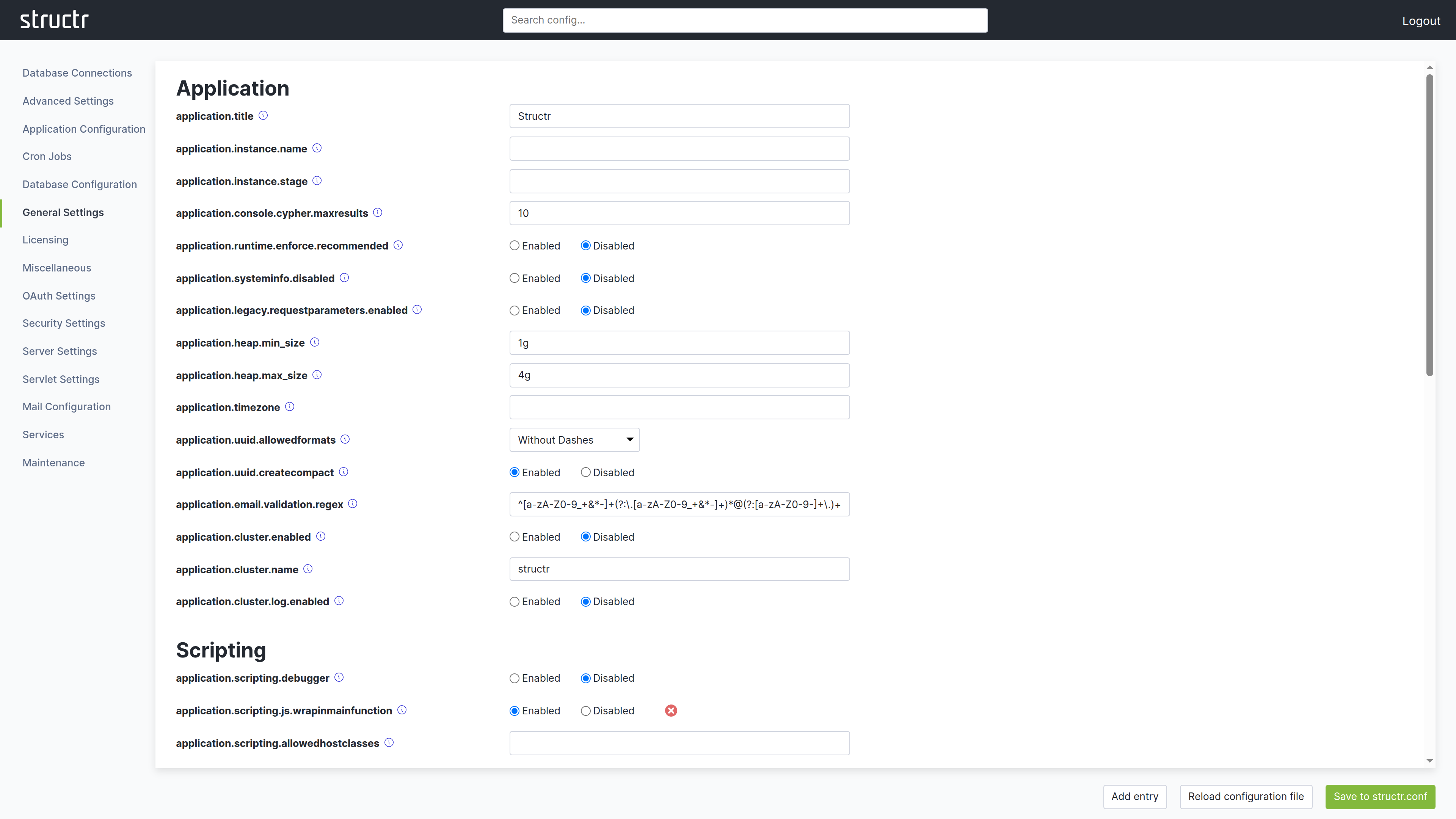
The Configuration Interface uses a different layout than other areas of the Admin UI. The header bar is present at the top, but it contains no main navigation menu. In the top right corner, you find a logout link to end your session in the Configuration Interface.
Instead of a menu, the secondary area below the header provides a search field that filters configuration options by name or description.
The main area is divided into two sections. The left side displays a list of categories. Depending on your screen resolution, this list may appear at the top instead of on the left. Click a category to display its settings on the right side. Each setting shows its current value, default value, and a description of its purpose.
At the bottom of the screen, you find buttons to create new configuration entries, reload the configuration file, and save your changes. When you modify a setting, click Save to structr.conf in the bottom right corner to persist your changes.
Some settings display a small red button next to them. Clicking this button resets the setting to its default value and saves the change automatically. You do not need to click the save button separately for these reset operations.
What You Can Configure
Settings are organized into categories such as application settings, database configuration, HTTP server options, security settings, and more. Most changes take effect immediately, though some require a server restart.
Beyond simple configuration values, the Configuration Interface is currently the only place where you can define cron expressions for user-defined functions. This allows you to schedule functions to run at specific intervals without writing additional code.
For a complete reference of all available settings, see the Settings chapter in the References section.
Basics
Admin User Interface
Only administrators can use the Structr Admin User Interface. Regular users cannot log in, and attempting to do so produces the error message User has no backend access. That means every Structr application with a user interface needs a Login page to allow non-admin users to use it. There is no built-in login option for non-admin users.